W2-D2: RCA — Graph, Causal & LLM-augmented
Table of Contents
- RCA — Graph, Causal & LLM-augmented
RCA — Graph, Causal & LLM-augmented
Mở đầu: từ “47 alert” thành “1 culprit”
Bạn đã có 1 cluster — gom 14 alert từ 3 service: payment-svc, checkout-svc, edge-lb. Cả 3 đều đang kêu. Câu hỏi gốc: service nào là gốc, service nào chỉ là nạn nhân?
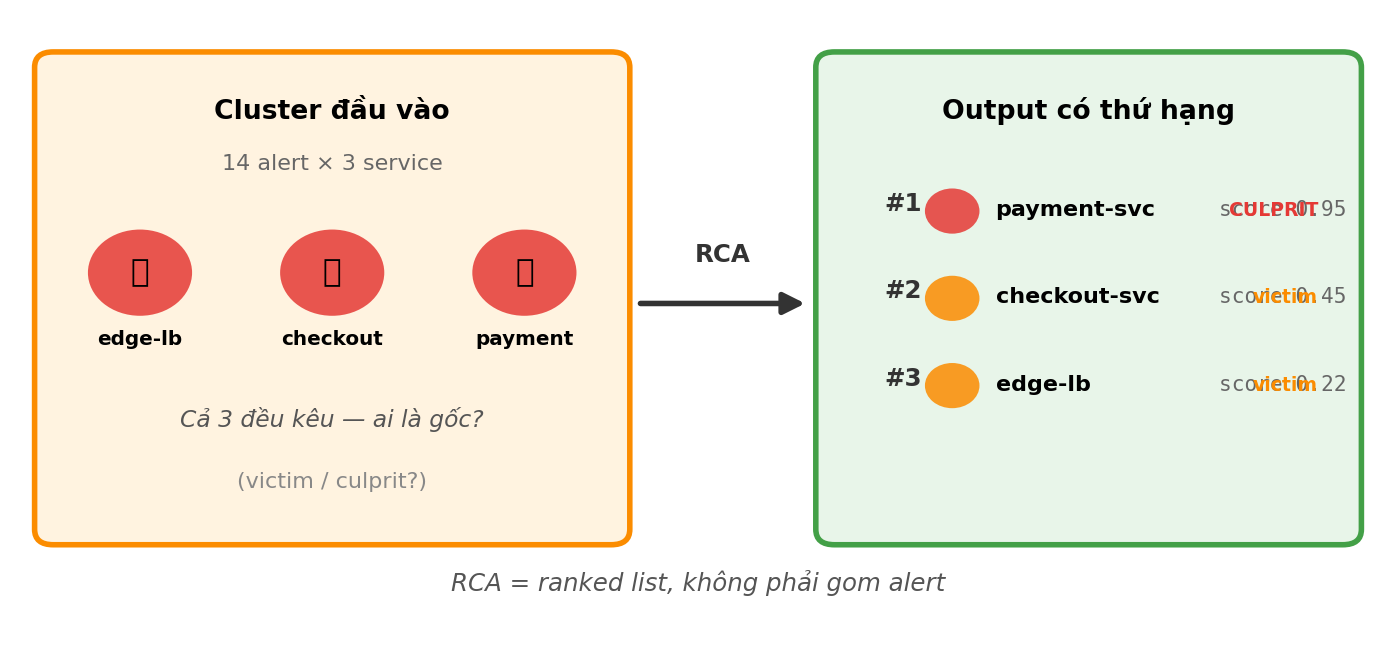
Đây là Root Cause Analysis (RCA). Hôm nay cover 3 cách làm RCA tự động:
- Graph traversal — dùng service graph để pick “service ở vị trí gốc nhất” trong cluster
- Causal inference — dùng metric time-series để xác định service nào degrade TRƯỚC
- LLM-augmented — hỏi LLM với context (history + graph) để suggest root cause + action
Cả 3 không loại trừ nhau — pipeline tốt combine cả 3 và return ranking, không phải 1 answer tuyệt đối.
💡 Quy tắc vàng: Đừng kỳ vọng RCA tự động đạt accuracy 100%. Mục tiêu thực tế: top-3 candidate chứa root cause đúng > 80% các case. Người vận hành (SRE) verify cuối cùng.
1. Vấn Đề: Phân biệt Culprit vs Victim
Khi payment-svc, checkout-svc, edge-lb cùng kêu alert, intuition đầu tiên: “service có nhiều alert nhất = root cause”. Sai.
Trong scenario chính:
| Service | Số alert | Vai trò thật |
|---|---|---|
payment-svc | 14 | CULPRIT (gốc thật) |
checkout-svc | 12 | Victim — vì depend on payment |
edge-lb | 9 | Victim — vì depend on checkout |
notification-svc | 6 | Victim — backlog Kafka do checkout chậm |
checkout-svc không phải gốc. Nó alert nhiều vì mọi user request đi qua nó — khi payment hỏng, checkout là chỗ đầu tiên hứng lỗi.
3 dấu hiệu phân biệt culprit vs victim:
| Dấu hiệu | Culprit có | Victim có |
|---|---|---|
| Timestamp | Alert SỚM nhất trong cluster | Alert muộn (sau khi cascade lan tới) |
| Vị trí trên graph | Là service được người khác GỌI VÀO | Là service đang GỌI VÀO service khác |
| Tính độc lập | Alert dù phần khác bình thường | Chỉ alert khi service khác hỏng trước |
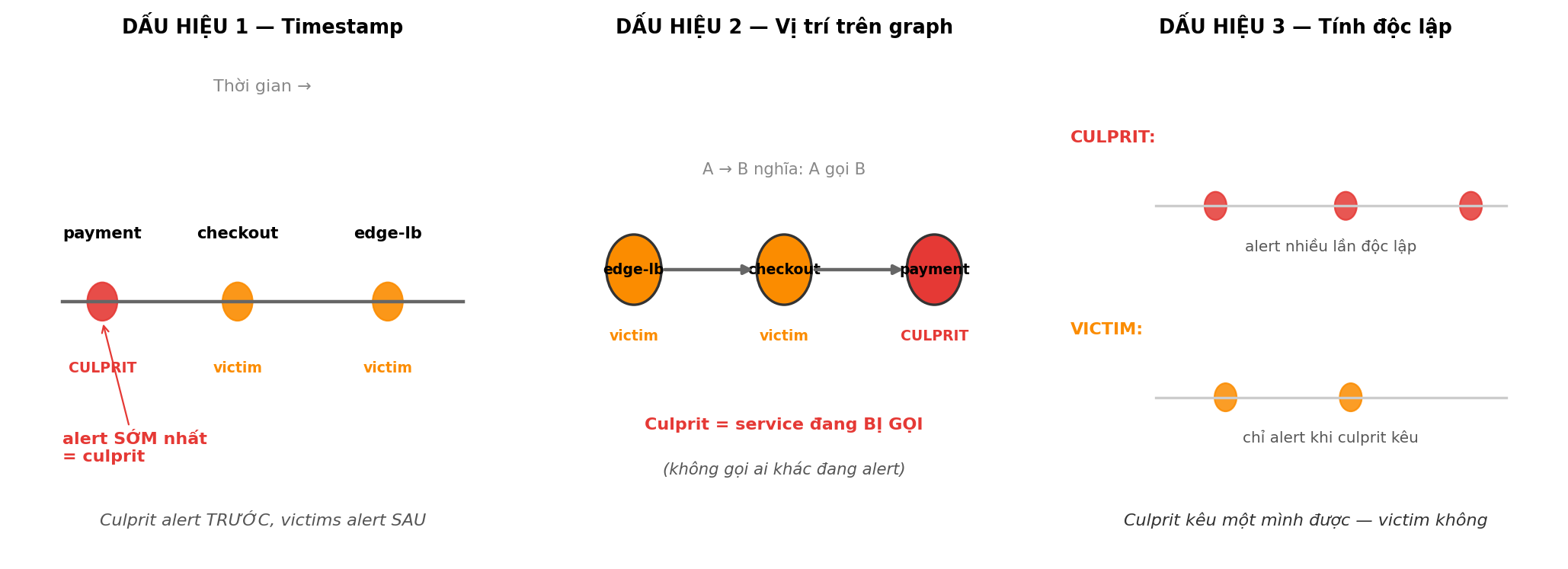
3 algorithm dưới đây lần lượt khai thác 3 dấu hiệu này.
2. Graph Traversal RCA
2.1 Insight
Trên service graph, mũi tên A → B nghĩa là A GỌI B. Khi B hỏng, A cũng hỏng theo. Tức là lỗi lan NGƯỢC chiều mũi tên — từ service bị gọi → các service đang gọi nó. (Service graph thường được dựng tự động từ trace data — xem OpenTelemetry service graph hoặc generator của Tempo.)
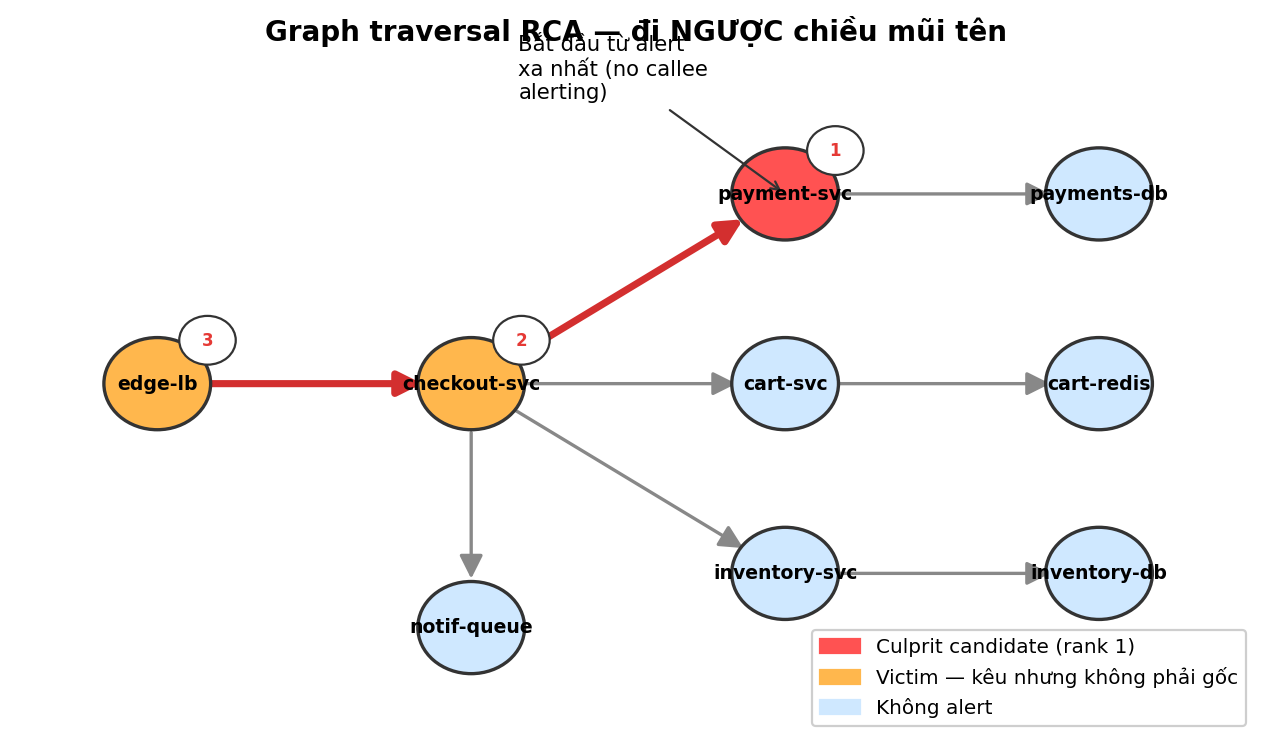
Nếu cluster có nhiều service đang alert, ai ở vị trí “sâu nhất” (không gọi ai trong số đang alert) thường là culprit.
2.2 Algorithm đơn giản — pick “sâu nhất”
Idea: lấy subgraph chỉ chứa service đang alert → service có out_degree thấp nhất (không gọi ai khác trong số đang alert) chính là candidate. Khi tie → ưu tiên in_degree cao (nhiều caller phụ thuộc).
Mental test: Cluster = [edge-lb, checkout-svc, payment-svc]:
edge-lb: in=0, out=1 (gọi checkout)checkout-svc: in=1, out=1 (gọi payment, bị edge-lb gọi)payment-svc: in=1, out=0 (không gọi ai trong cluster — terminal)
→ payment-svc được chọn ✓ Khớp scenario.
2.3 PageRank scoring
Pick top-1 binary không robust. Khi cluster có 8 service và 2 candidate sát điểm nhau, ta cần score liên tục thay vì 1-or-0.
Idea PageRank: node được “vote” bởi các node link tới nó. Trong RCA, chạy PageRank trên reverse graph — service được nhiều caller phụ thuộc → score cao. (networkx PageRank docs · PageRank trên Wikipedia)
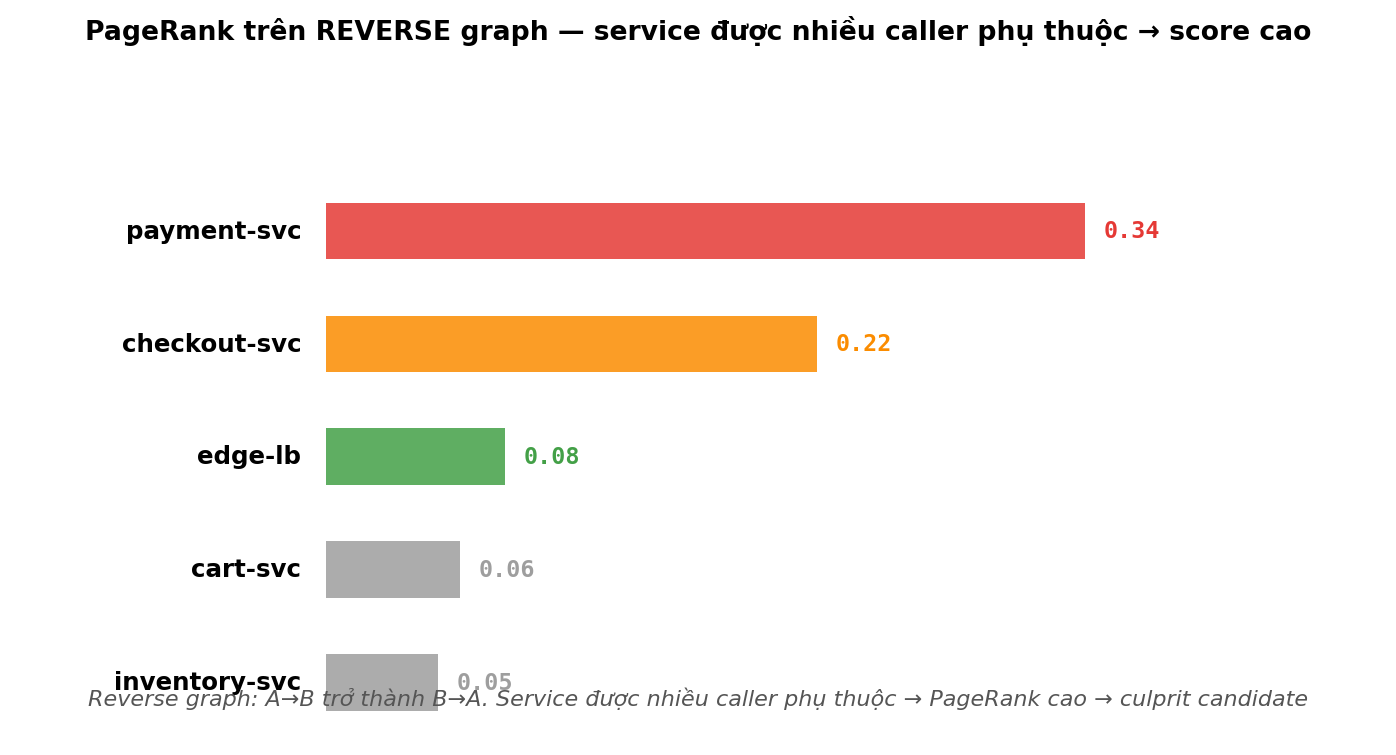
Implementation 1 dòng: nx.pagerank(subgraph.reverse(copy=True), alpha=0.85). Confidence top-1 = score_top / sum(scores) — vd 0.42 → moderately confident.
2.4 Kết hợp với timestamp
Graph alone không xử lý được “service A đứng sâu nhưng alert sau service B đứng trên”. Bổ sung temporal: service alert SỚM nhất có boost.
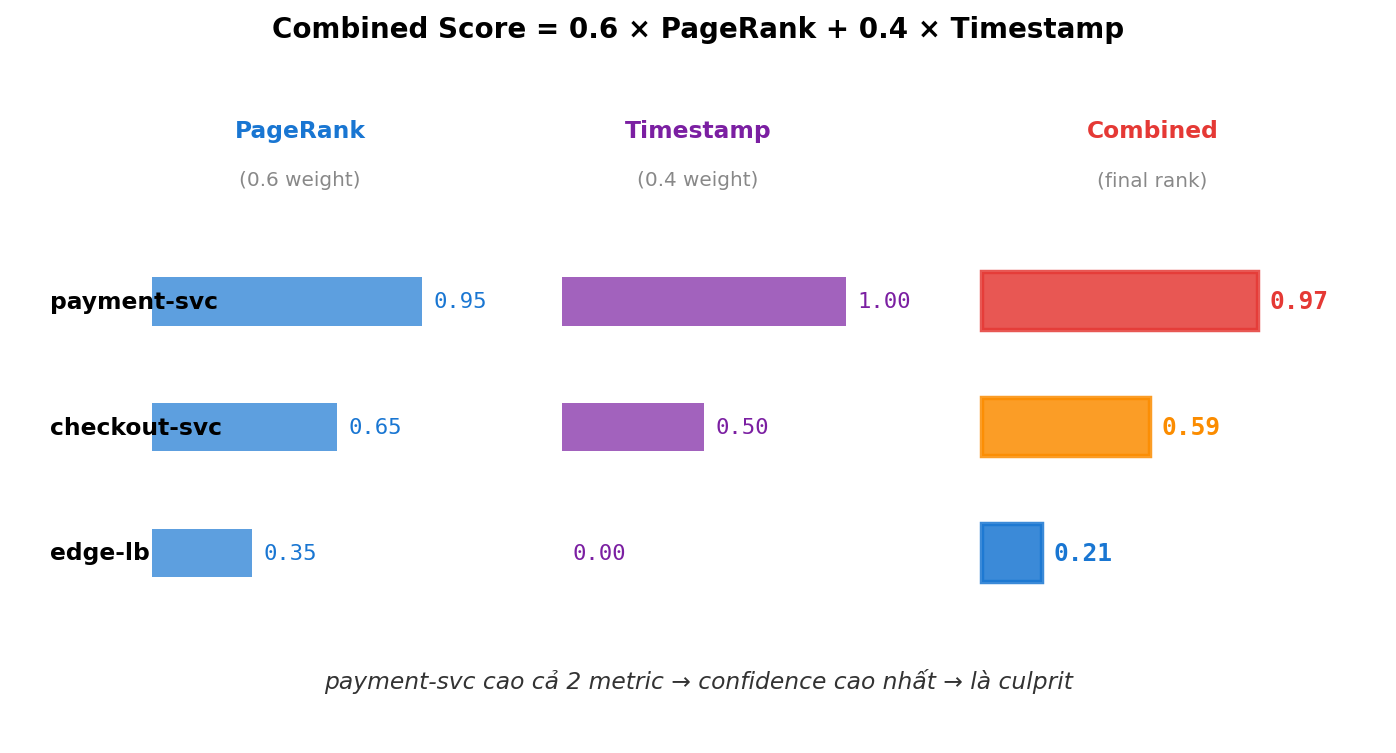
Công thức: final_score = 0.6 × pagerank_norm + 0.4 × timestamp_score
pagerank_norm= PageRank chia cho max trong cluster (về [0, 1])timestamp_score= service alert sớm nhất → 1.0, muộn nhất → 0.0, linear giữa
Trọng số 0.6 / 0.4 có thể tune. Khi service graph yếu (thiếu edge), giảm xuống 0.4 / 0.6 để temporal nặng hơn.
2.5 Edge case — terminal noise
Node “sâu nhất” có thể là database hoặc cache. Nếu DB alert vì pool full do app leak connection, DB là victim, không phải culprit.
Giải pháp:
- Tag node với
criticality+typetrong service graph (đã có sẵn trongservices.json) - Nếu top-1 là store (DB / cache), check xem nó alert TRƯỚC hay SAU service ứng dụng phụ thuộc nó
- Alert SAU → app là culprit, DB là victim
- Alert TRƯỚC → DB là culprit thật (vd: DB crash, network partition)
2.6 Beyond shortest path — 3 graph algorithm khác
Shortest path / hop distance trả lời 1 câu: “2 service có gần nhau không?”. Production RCA dùng thêm 3 algorithm khác, mỗi cái trả lời 1 câu khác nhau.
| Algorithm | Câu hỏi | Khi nào dùng |
|---|---|---|
| Shortest path (đã dùng) | “2 service có gần nhau không?” | Gom alert cùng cascade chain |
| Reverse PageRank (xem §2.3) | “Service nào được nhiều caller phụ thuộc nhất?” | Rank culprit candidate trong cluster |
| Betweenness centrality | “Service nào là chokepoint?” | Tìm node mà sự cố sẽ cắt traffic toàn bộ. nx.betweenness_centrality(g) |
| Community detection (Louvain/Leiden) | “Subsystem boundary ở đâu?” | Chia ownership team, scope alert theo subsystem. nx.community.louvain_communities |
Ví dụ cụ thể: checkout-svc được gọi bởi 4 caller (edge-lb, mobile-bff, partner-api, internal-tool).
- Shortest path:
checkout-svccáchpayment-svc1 hop — bình thường - Reverse PageRank:
checkout-svccó score cao (nhiều caller depend) — candidate culprit - Betweenness:
checkout-svcchokepoint vì mọi user request đều đi qua — hỏng nó = downtime toàn site - Community detection:
checkout-svc+payment-svc+cart-svccùng community “order flow”;recommender-svcở community khác → alert recommender không nên gom vào cluster checkout
Đọc thêm: networkx centrality algorithms · Louvain method trên Wikipedia.
2.7 Khi topology-based RCA fails
Graph approach giả định “có dependency rõ ràng giữa 2 service”. 4 case sau phá vỡ giả định đó:
| Case | Vấn đề | Workaround |
|---|---|---|
| Serverless / FaaS | Lambda không có identity bền — mỗi cold start là instance khác. Edge “A→B” mơ hồ vì B là collection of ephemeral runs. | Coarse-grain — coi mọi invocation của 1 function là 1 node logic. Mất visibility per-instance. |
| Async / event-driven | Service A publish vào Kafka, service B consume. Không có request/response trực tiếp. Producer-consumer mapping là business logic. | Dùng topic làm node trung gian: A → topic → B. Hop count tăng nhưng giữ được causal direction. |
| Multi-tenant shared infra | DB shared giữa 10 service. Khi DB chậm, 10 service alert. Topology nói “DB là culprit” — đúng nhưng không actionable. Cần biết tenant nào gây chậm. | Thêm tenant_id vào alert metadata. RCA cần đi xuống tenant level, không dừng ở service. |
| Service mesh abstraction | Istio thêm sidecar proxy giữa mỗi service. Khi proxy hỏng, alert hiện ở service nhưng causal là mesh layer. | Thêm sidecar làm “shadow node” cho mỗi service, hoặc tag alert component=sidecar. |
Pattern chung: khi topology approach fails, đừng vứt graph — bổ sung dimension khác (tenant, component, queue) hoặc fallback về causal inference (§3). Đó là lý do production RCA combine nhiều signal.
3. Causal Inference RCA
Graph traversal chỉ cần topology + alert, không cần metric data. Causal inference ngược lại — chỉ cần metric time-series, không cần graph.
3.1 Granger causality — direction theo thời gian
Câu hỏi: “Metric A của payment-svc có ‘cause’ metric B của checkout-svc không?”
Granger test trả lời: nếu giá trị quá khứ của A giúp dự đoán B tốt hơn so với chỉ dùng quá khứ của B, ta nói A Granger-cause B.
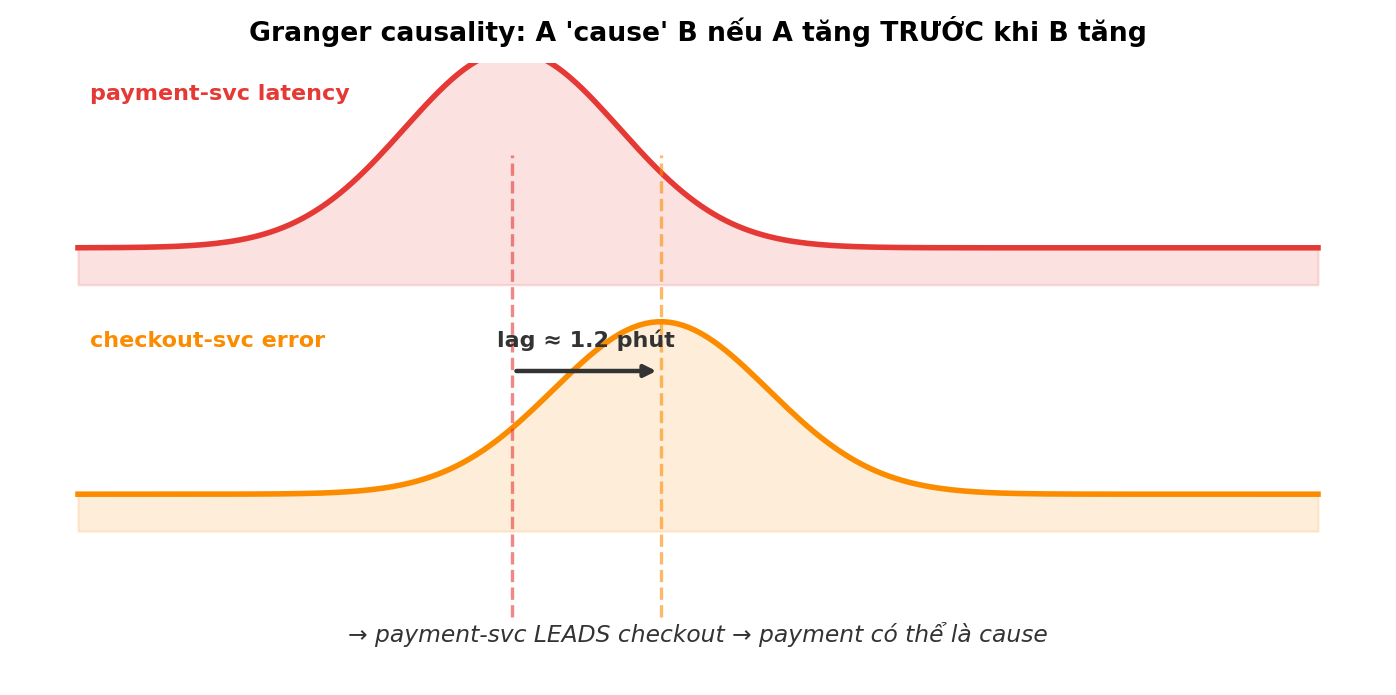
Granger causality không phải causation theo nghĩa philosophy — nó là temporal precedence + predictive. Nhưng trong AIOps đủ tốt. (statsmodels API · QuantStart tutorial Python)
Cách dùng: gọi statsmodels.tsa.stattools.grangercausalitytests với cặp series (B, A) và maxlag=5. Lấy min(p_value) qua các lag. p < 0.05 → A có vẻ Granger-cause B.
3.2 Cảnh báo về Granger
- Yêu cầu stationary — series không có trend / seasonality. Phải
np.diff()trước, hoặc STL decompose (đã học bên anomaly detection). - Chỉ pairwise — test A→B, không quan tâm trong context có C. Có thể nói “A causes B” trong khi thực tế cả 2 đều do C cause.
- Cần sample size lớn — ≥ 50 data points, lý tưởng 200+. 5 phút × scrape 15s = 20 điểm — không đủ. Phải dùng raw metric, không chỉ alert.
Với constraint sample size, Granger không phải first-line tool. Nó hữu ích khi có sẵn time-series dài + muốn build causal graph offline.
3.3 Cross-correlation lag — đơn giản hơn
Một approximation: chỉ đo lag mà 2 metric tương quan max.
Cách dùng: quét lag k trong khoảng [-30, +30] giây, tính np.corrcoef(A[t], B[t+k]), lấy k cho |corr| max.
| Lag | Ý nghĩa |
|---|---|
k > 0 | A đi TRƯỚC B → A có thể cause B |
k < 0 | B đi TRƯỚC A → B có thể cause A |
k = 0 | Cùng lúc → không kết luận direction |
Trong scenario chính: đo payment-svc.latency_p99 vs checkout-svc.latency_p99. Lag tốt nhất ≈ 5s — payment dẫn trước checkout 5 giây → payment có vẻ cause.
3.4 PC algorithm — full causal graph (FYI)
PC algorithm (Peter-Clark) build causal DAG từ data:
- Start với fully connected undirected graph
- Remove edge nếu conditional independence test PASS
- Orient remaining edges theo collider patterns
Library: causal-learn, pgmpy. Đây là research direction, không phải go-to cho production AIOps. Nhắc để biết.
3.5 Chọn tool nào
| Tình huống | Tool tốt |
|---|---|
| Có service graph trust được | Graph traversal — fast, deterministic |
| Service graph thiếu / không đầy đủ | Causal — học edge từ data |
| Đang trong middle of incident | Graph + temporal (§2.4) — phản hồi < 1s |
| Post-mortem deep dive | Causal + manual review |
Cho bài tập: dùng graph traversal + temporal là chính. Causal đề cập trong reflection.
4. LLM-Augmented RCA
Đến đây bạn có top-3 candidate. LLM (option, không bắt buộc) giúp:
- Phân loại root cause (“connection_pool_exhaustion” / “slow_query” / “rebalance_storm” / …)
- Suggest action dựa trên incident history
- Reasoning — giải thích vì sao service X là root cause
4.1 Pipeline tổng
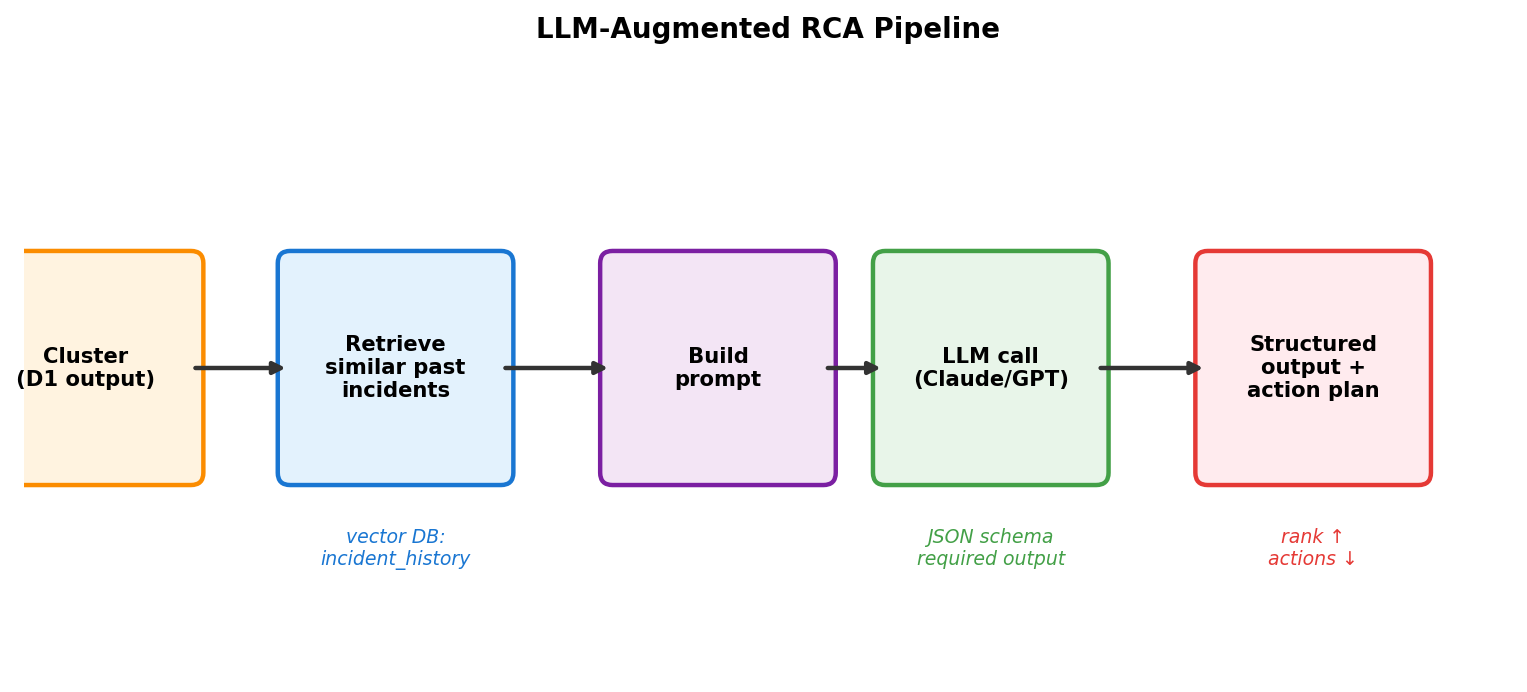
4.2 Retrieval — similar past incidents
incidents_history.json có 30 incident lịch sử. Cần pick top-K similar nhất với cluster hiện tại.
Heuristic score (0–1):
+0.4nếuhistory.root_cause_service∈cluster.services+0.2mỗi service overlap giữacluster.servicesvàhistory.services_involved(max +0.4)+0.2nếu cùngseverity
Pick top-K (default K=3) các history có score ≥ 0.2.
Nâng cao: sentence-transformer embed → cosine similarity → top-K. (Library: SBERT.net — model all-MiniLM-L6-v2 chỉ ~80MB, chạy CPU được.) Đề cập để biết direction. Cho bài tập, keyword approach đủ.
4.3 Prompt template
Prompt phải có 4 phần: system instruction, context, examples (similar incidents), task. (Đọc thêm: OpenAI Structured Outputs guide, Anthropic prompt engineering.)
Cấu trúc prompt (4 phần):
- System — role + format constraint (vd: “You are a senior SRE. Respond only in valid JSON.”)
- Context — cluster metadata + top-3 candidate từ graph RCA + service graph subset
- Examples — 3 incident lịch sử tương tự (RAG retrieval) với root_cause + remediation
- Task + schema — yêu cầu output JSON với enum cố định cho
class, dảiconfidence ∈ [0, 1], listactionsnon-empty
Enum cho root_cause_class (10 nhãn): connection_pool_exhaustion, slow_query, memory_leak, rebalance_storm, deadlock, network_partition, bad_deploy, config_push, tls_expiry, ddos, other.
4.4 Gọi LLM
Implementation thực tế gồm 3 bước cố định:
- Build context block (cluster info + top-3 candidate + 3 similar history) → format vào prompt template
- Gọi LLM với
temperature=0.2(RCA cần consistent, không creative) +response_format=json_object(OpenAI) / structured output schema (Anthropic) - Log toàn bộ prompt + raw response vào file để debug + audit
Set timeout=10.0 và max_retries=2 — LLM hang là failure mode phổ biến, đừng để endpoint stuck.
4.5 Hallucination guard (OpenAI Reliability cookbook)
LLM có thể trả root_cause = service KHÔNG có trong cluster. Validate trước khi dùng:
4 check bắt buộc trước khi tin output LLM:
root_cause∈cluster.services(LLM hay đoán bừa service không tồn tại)class∈ enum đã định nghĩa (không phải free text)confidence ∈ [0, 1](float, không phải string)actionslà list non-empty
Nếu invalid → fallback: top-1 từ graph RCA + class="other" + actions=["Investigate manually"]. Endpoint không bao giờ crash vì LLM bậy.
4.6 Cost awareness
gpt-4o-mini (giá Jun 2026 ≈ $0.15 / 1M input, $0.60 / 1M output):
- Prompt ~2500 tokens × 1 call = $0.0004
- 1 batch incident = 3-5 cluster → 3-5 call = ~$0.002
- 1 năm production: 100 incident/ngày × $0.002 = $73/năm
Cheap. Nhưng nếu naive — gọi LLM cho mỗi alert thay vì mỗi cluster — sẽ tốn 50-100×. Đừng làm vậy.
5. Putting It Together — Final RCA Function
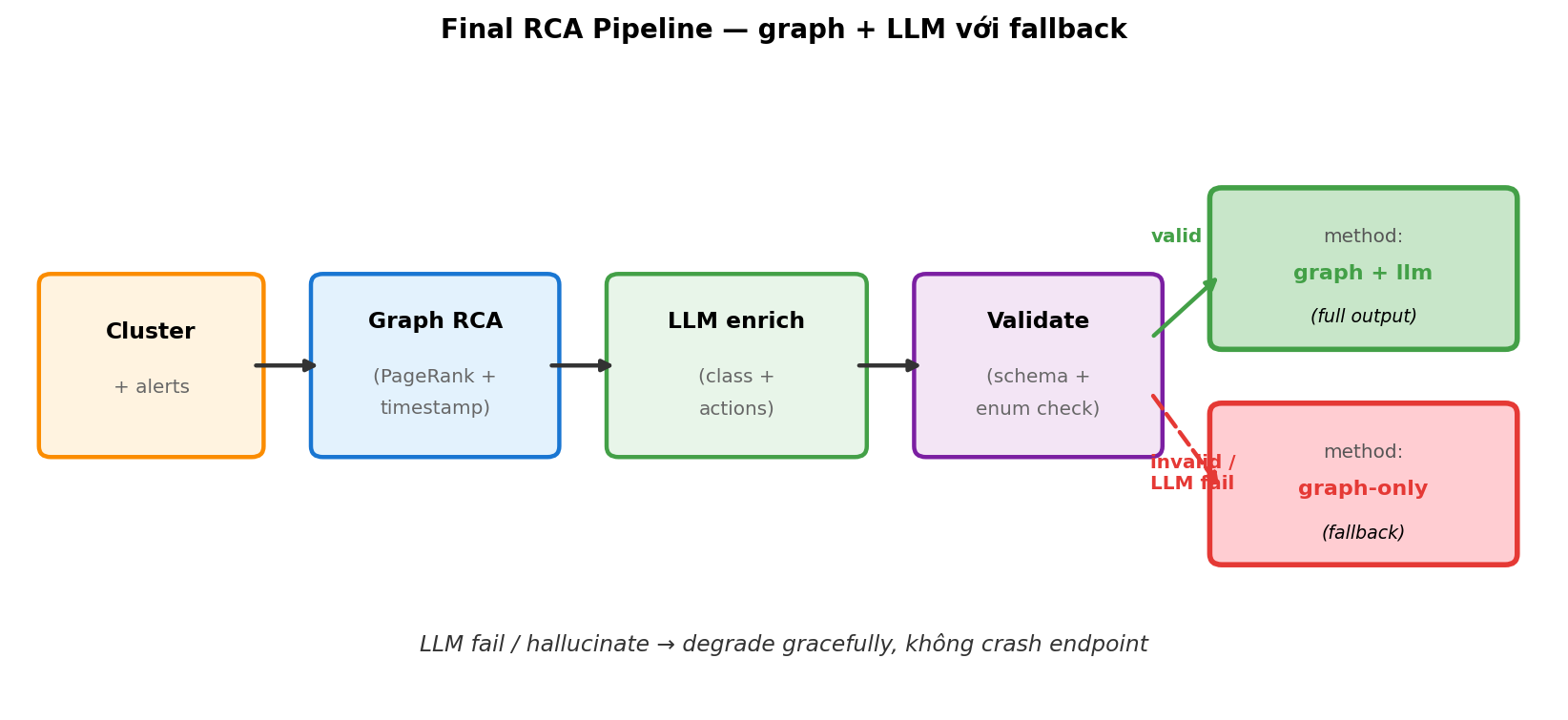
Pipeline lái logic theo flowchart trên:
- Tính
candidates = rca_combined(cluster, alerts, graph)— luôn chạy - Build graph context (subgraph cluster + service edges) — luôn chạy
- Nếu có LLM enabled → gọi
call_llm(), validate. Output OK → return. Output sai/timeout → fallback (xem 4) - Fallback path:
root_cause = candidates[0],class = "other",confidence = candidates[0].score,actions = ["Investigate manually"],method = "graph-only-fallback"
Mỗi return path đều có field method ghi rõ source — quan trọng cho audit khi sai.
6. Industry landscape — bạn đang xây gần ai?
Đây là một số công cụ RCA đang được dùng trong industry. Mỗi cái có triết lý riêng — không có cái nào “đúng nhất”:
| Product / Tool | Triết lý cốt lõi | Mạnh ở đâu |
|---|---|---|
| Dynatrace Davis | Topology là source of truth → causal AI dựa trên service map (Smartscape) | Auto-detect dependency, top-1 root cause < 5s cho stack đã instrument |
| BigPanda | ML cluster alerts trước, RCA bằng pattern matching, agnostic với topology | Multi-vendor alert ingestion, dedup ở quy mô rất lớn |
| Moogsoft | “Situations” — gom alert thành unit có nghĩa, signal-to-noise tối đa | Noise reduction, alert correlation thuần (pioneer của ngành) |
| Datadog Watchdog | Bundle anomaly + correlation + APM trong cùng nền tảng | Full-stack observability, ít tool, tích hợp metric/log/trace native |
| Causely | Causal AI không cần topology giả định, học causal graph từ data | Microservices không có service map rõ ràng / hay đổi |
| Prometheus AlertManager (OSS) | Dedup + grouping ở mức routing — không claim RCA | Foundation cho self-built correlator, không vendor lock-in |
| Robusta (OSS, k8s) | Alert smart-routing + auto-remediation playbook | K8s-native, fix common issue tự động |
| Grafana Sift | “Investigation as first-class” — RCA workflow tích hợp dashboard | Khi đã dùng Grafana stack đầy đủ |
Pipeline bạn xây hôm nay (graph + temporal + classifier) gần với Dynatrace Davis nhất — assume service graph tin được. Trade-off: khi graph thiếu/sai, output bị lệch. Causely không có giả định đó nhưng phải có time-series dài để học causal — pipeline bạn dùng graph để “shortcut” qua causal inference. Cả 2 đều đúng cho domain khác nhau.
Đọc tiếp:
- Dynatrace Davis architecture deep-dive
- BigPanda product overview
- Moogsoft Situations whitepaper
- Robusta GitHub
- Causely.io
- Grafana Sift docs
7. Bài tập — Build RCA của bạn
Task: Implement RCA pipeline trong assignment.ipynb — gom logic graph traversal, retrieval và (optional) LLM enrichment vào notebook.
Quy ước nộp bài (auto-grader chặt):
- Branch
main- Path:
aiops-<tên>/w2/d2/(lowercasew2+d2)- File:
assignment.ipynb+FINDINGS.md(HOA) +SUBMIT.md(HOA) +results/rca_output.json- Sai naming → 1 điểm.
7.1 Input
Output từ bài tập trước: results/cluster_summary.json (từ aiops-<tên>/w2/d1/)
Tải dataset:
- Alerts raw (20 alert): alerts_sample.jsonl
- Service graph: services.json
- Incident history (30 incidents): incidents_history.json
Lưu vào aiops-<tên>/w2/d2/dataset/.
Không cần API key. Default path dùng graph + retrieval thuần.
7.2 Output
results/rca_output.json:
{
"clusters_analyzed": 3,
"results": [
{
"cluster_id": "c-001-000",
"graph_top3": [["payment-svc", 0.82], ["checkout-svc", 0.45], ["edge-lb", 0.30]],
"root_cause": "payment-svc",
"class": "connection_pool_exhaustion",
"confidence": 0.84,
"actions": ["Rollback payment-svc v3.2 → v3.1", "Increase pool 50 → 100"],
"reasoning": "...",
"similar_incidents": ["INC-2025-11-08", "INC-2026-05-10"],
"method": "graph+llm"
}
]
}
Cũng viết FINDINGS.md ≥ 100 từ:
- Cluster chính: root cause là gì + lý do
- Confidence — có dám deploy auto-remediation dựa trên output này không?
- 1 case mà bạn không chắc — vì sao
7.3 Steps — required (không cần API)
- Tạo notebook
assignment.ipynbtrongaiops-<tên>/w2/d2/ - Import output từ bài tập trước (
cluster_summary.json) - Build graph từ
services.json - Cho mỗi cluster: chạy graph + temporal scorer → top-K candidates
- Load
incidents_history.json→ retrieve top-3 similar (keyword similarity) - Classifier (required): lấy
class+actionstừ top-1 similar incident (kNN-style) - Validate output schema + fallback nếu retrieval rỗng
- Write
rca_output.json+FINDINGS.md+SUBMIT.md
7.4 Bonus paths — đọc thêm / mở rộng (optional, không tăng/giảm điểm chính)
Chọn 1 trong 3 nếu muốn đi sâu hơn — viết kết quả + so sánh trong FINDINGS.md:
- Bonus 1 — Decision tree: train
sklearn.tree.DecisionTreeClassifiertrên 30 incident với features (services_set, severity_max, time_burst_pattern) → labelroot_cause_class. Compare accuracy với kNN top-1. - Bonus 2 — TF-IDF embedding: thay keyword similarity bằng
sklearn.feature_extraction.text.TfidfVectorizertrênsummary + services→ cosine similarity → top-K. Compare với keyword retrieval. - Bonus 3 — LLM enrichment: dùng Groq free tier hoặc paid OpenAI/Anthropic — thay step 6 bằng LLM call với prompt structure §4.3. Compare class label vs kNN top-1. Đọc thêm Anthropic “Building Effective Agents” trước khi làm.
FINDINGS.md phải nêu: chọn bonus nào? Nếu KHÔNG chọn → tại sao retrieval-only đã đủ?
7.5 Acceptance
- Notebook chạy được, ≥ 3 cell có output
rca_output.jsonvalid, cógraph_top3+root_cause+class- Code có ít nhất 1 trong:
networkx,nx.,graph,subgraph - Code có 1 indicator của retrieval:
similar,top_k,_similarity,cosine,tfidf,kNN FINDINGS.md≥ 100 từ với RCA analysis cụ thể trên cluster của bạn- Bonus path: nếu chọn, kết quả so sánh được trình bày trong FINDINGS.md; nếu không chọn, giải thích lý do retrieval-only đã đủ
8. EOD Checkpoint
Trong SUBMIT.md, trả lời 3 câu — mỗi câu dựa trên cái bạn ĐÃ thấy/làm, không phải định nghĩa:
Confidence của top-1 trong cluster lớn nhất bạn xử lý là bao nhiêu? Nếu phải set threshold để auto-rollback (không cần SRE confirm), bạn pick số nào? Lý do?
Variant bạn chọn cho classifier (A rule-based / B free LLM / C paid LLM). Chạy thực tế ra sao? Trade-off với variant bạn không chọn?
Đọc bảng Industry landscape (§6) — pipeline bạn xây gần product nào nhất? Trong domain GeekShop (e-commerce, alert volume cao, service map tương đối ổn định), lựa chọn đó hợp lý hay nên đổi?
Không có câu hỏi recall lý thuyết. Câu trả lời “viết qua loa” sẽ thấy rõ ngay khi đọc.
9. Tài liệu tham khảo
- “Detecting Causes of Performance Anomalies in Microservices” — Microsoft Research, arxiv.org
networkxcentrality + PageRank: https://networkx.org/documentation/stable/reference/algorithms/centrality.htmlstatsmodelsGranger causality: https://www.statsmodels.org/stable/generated/statsmodels.tsa.stattools.grangercausalitytests.html- “You Don’t Have a Search Problem, You Have a Ranking Problem” — Charity Majors, Honeycomb blog: https://www.honeycomb.io/blog/you-dont-have-a-search-problem-you-have-a-ranking-problem