W2-D1: Alert Correlation — Từ Noise Sang Signal
Table of Contents
- Alert Correlation — Từ Noise Sang Signal
- Mở đầu: Đêm pager kêu
- 1. Vì sao alert flood là cơn ác mộng?
- 2. Layer 1 — Dedup (gộp alert trùng lặp)
- 3. Layer 2 — Time-Window (gom alert gần nhau về thời gian)
- 4. Layer 3 — Topology (gom alert theo cấu trúc service)
- 5. Layer 4 (Bonus) — Semantic Similarity
- 6. Production Patterns
- 7. Bài tập — Build correlator của bạn
- 8. EOD Checkpoint
- 9. Tài liệu tham khảo
Alert Correlation — Từ Noise Sang Signal
Mở đầu: Đêm pager kêu
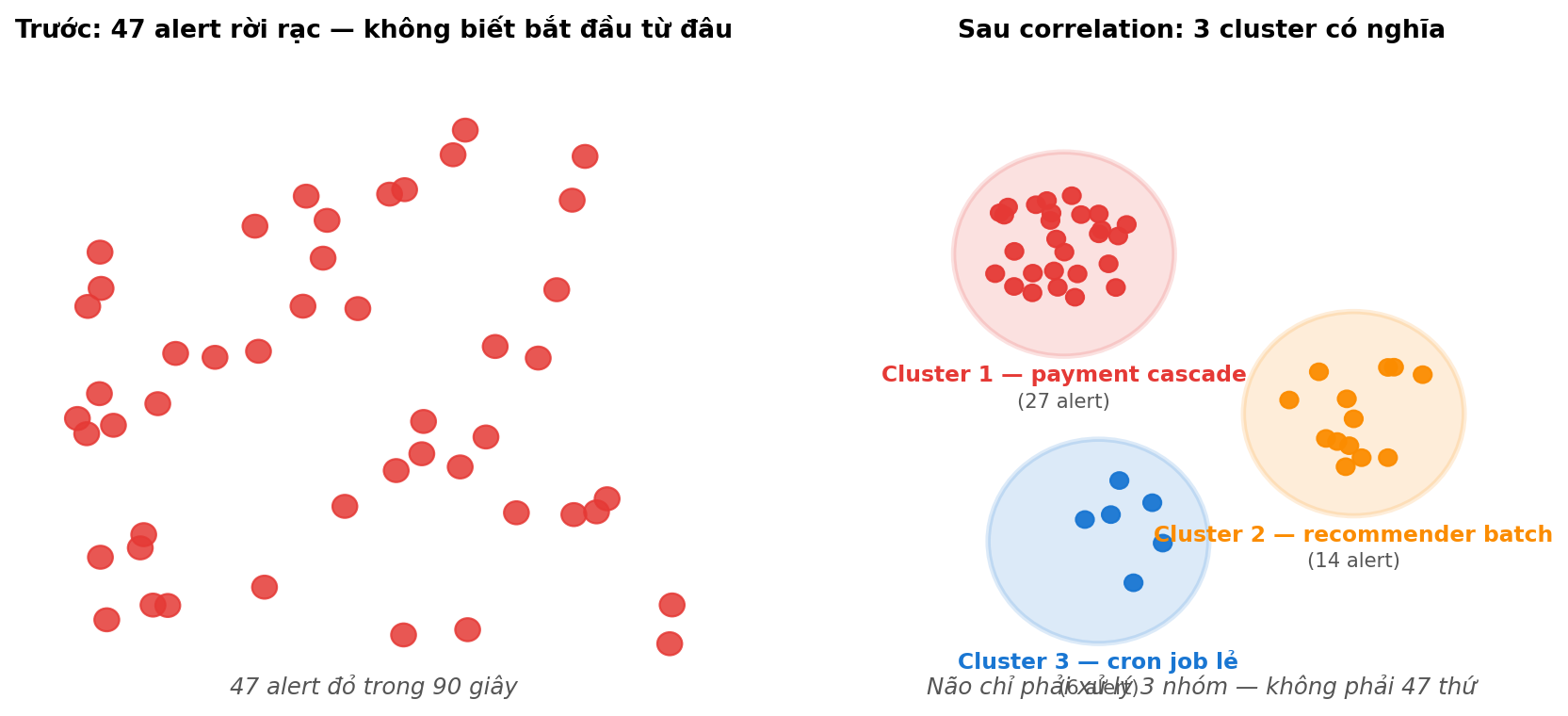
Tưởng tượng bạn vừa thiu thiu ngủ. 02:14 sáng. Điện thoại rung — pager báo. Bạn mở laptop ra. Trên dashboard hiện ra cảnh này:

47 alert đỏ rực trong 90 giây. 7 service khác nhau cùng kêu cùng lúc. Bạn còn chưa kịp uống ngụm nước.
Câu hỏi đầu tiên trong đầu: “Cái nào là gốc? Cái nào chỉ là hệ quả?”
Vấn đề không phải KHÓ — là QUÁ NHIỀU
Nếu chỉ có 1 alert (“payment-svc bị crash”), bạn biết phải làm gì: vào log, đọc metric, tìm cause. Xong trong 15 phút.
Nhưng 47 alert một lúc thì khác. Bạn không thể đọc 47 thứ song song. Não bị quá tải. Bạn mất 10 phút chỉ để đọc hết alert list — chưa kịp bắt đầu fix.
Bài này về cách gộp 47 alert thành 3 nhóm có nghĩa, thường gọi là cluster. Khi đó não bạn chỉ phải đối mặt với 3 thứ thay vì 47.
💡 Quy tắc vàng: Correlation KHÔNG tìm root cause. Nó chỉ rút gọn số việc cần làm sau đó. Hai chuyện hoàn toàn khác nhau.
1. Vì sao alert flood là cơn ác mộng?
1.1 Alert fatigue — bệnh nghề nghiệp của on-call
Một engineer on-call trung bình nhận 20-50 alert mỗi ngày. Mỗi cái đều “khẩn cấp”.
Khảo sát VictorOps 2023 (800 engineer) chỉ ra:
- 67% engineer nhận > 10 alert mỗi ca trực
- 45% thừa nhận đã từng TẮT notification của 1 alert vì noisy
- MTTR (thời gian fix sự cố) tăng 2.4× khi có alert flood
Hệ quả? Engineer mất niềm tin vào hệ thống. Họ ignore alert. Đến khi có alert thật sự nguy hiểm — không ai nhìn.
1.2 Khi 1 service hỏng, không bao giờ chỉ mình nó
Production system có 1 sự thật khó tránh: mọi thứ đều dependency với nhau. Khi payment-svc hỏng, nó kéo theo 4-5 service khác cùng kêu alert.
→ 1 gốc, 5 hệ quả. Bạn cần biết: chỉ 1 trong số chúng là cause thật, còn lại là tiếng vang.
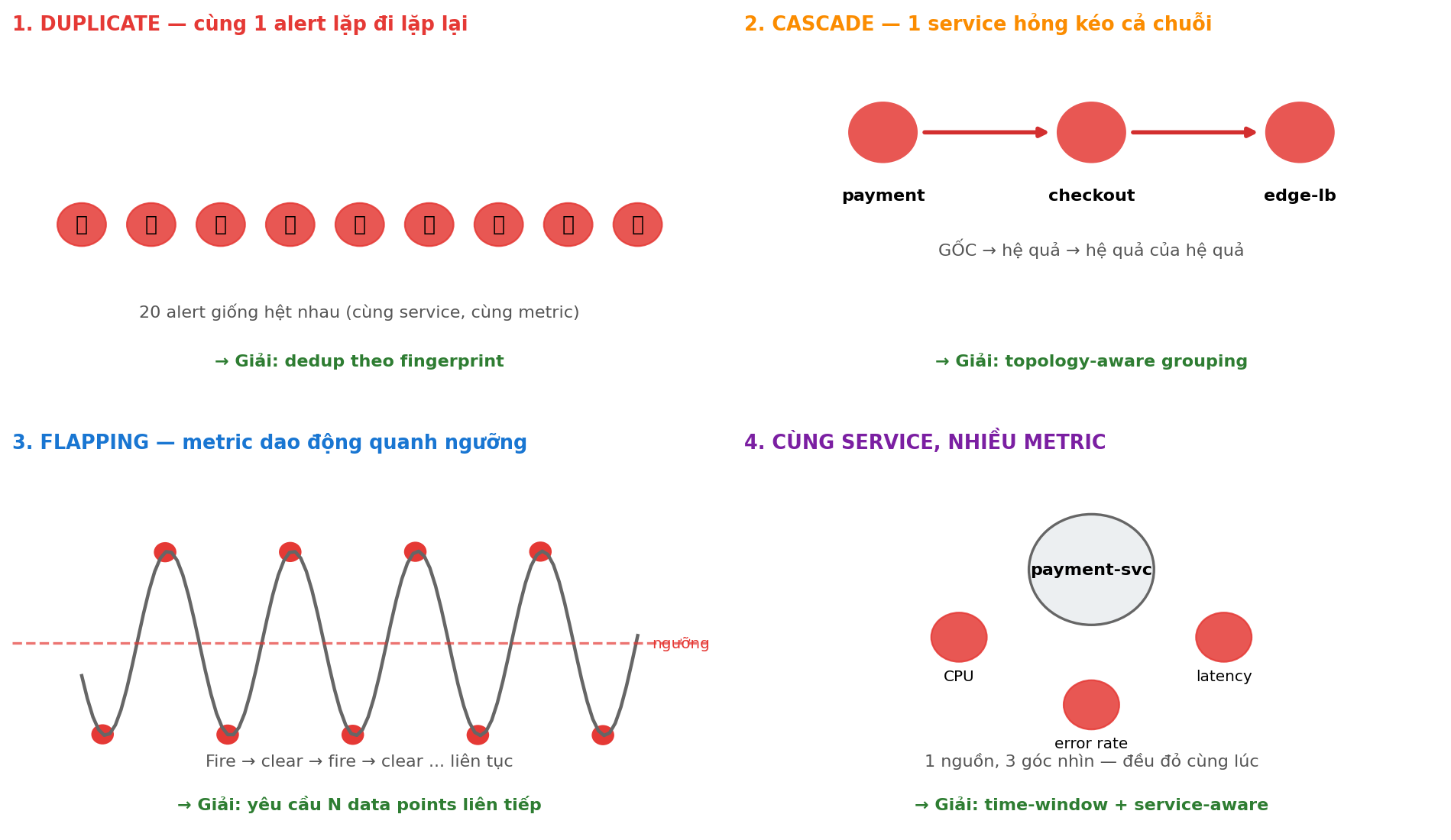
1.3 4 loại alert flood phổ biến
47 alert đêm qua không phải 47 thứ khác nhau. Thực ra là tổ hợp của 4 dạng — mỗi dạng cần kỹ thuật giải khác nhau:
1.4 Mục tiêu cụ thể của bạn
Cho 20 alert đầu vào (từ alerts_sample.jsonl), output 3-5 cluster trong đó:
- Mỗi cluster có metadata:
cluster_id,alert_count,services,time_range,max_severity - 0 orphan: alert nào không khớp ai → vẫn ra 1 cluster size = 1
20 → 3-5 cluster nghĩa là giảm 75-85% số thứ phải xử lý. Đó là cách đo correlation work hay không.
2. Layer 1 — Dedup (gộp alert trùng lặp)
Ý tưởng: cùng 1 alert fire đi fire lại → không cần tạo nhiều cluster, chỉ cần đếm số lần.
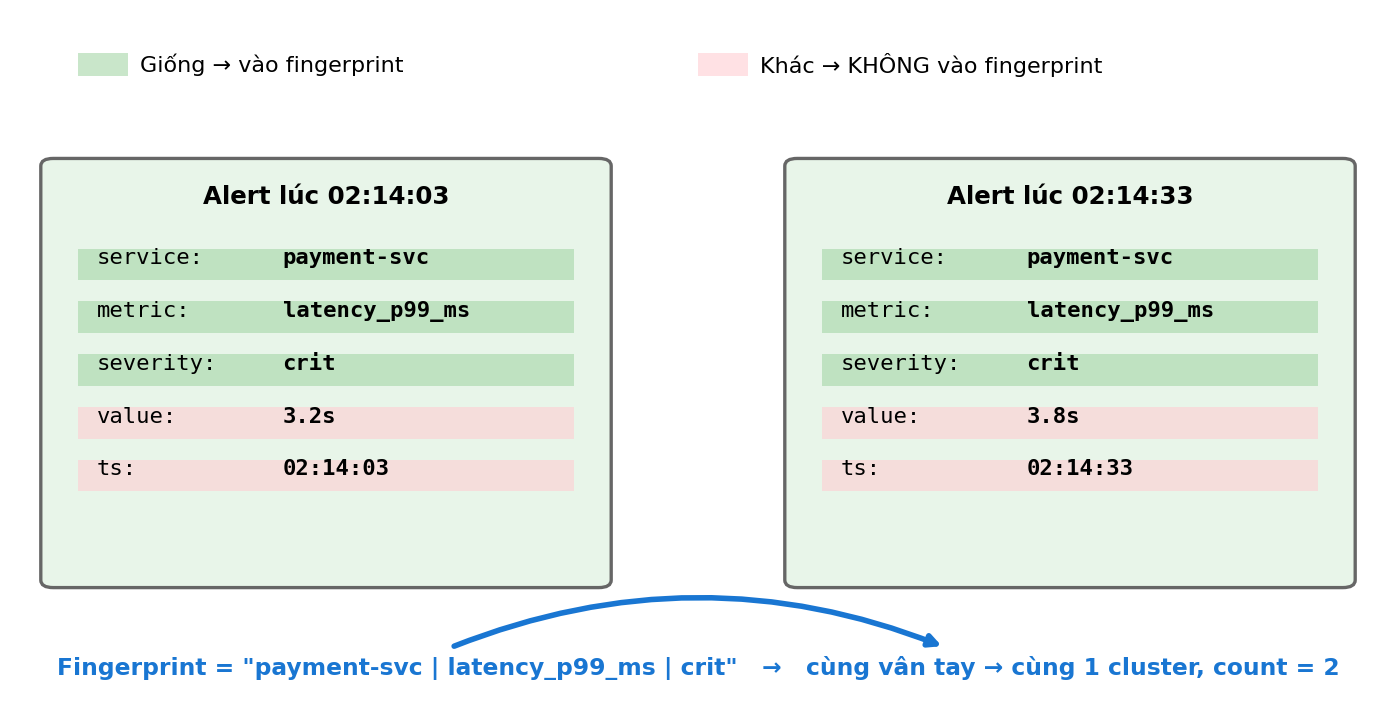
2.1 Fingerprint — “vân tay” của alert
Hãy nghĩ về vân tay con người. Cùng 1 người chạm vào cốc 5 lần → ta thấy 5 dấu — nhưng đó vẫn là 1 người.
Alert cũng vậy. Mỗi alert có 10-20 field. Hầu hết field thay đổi mỗi lần fire (timestamp, value), nhưng một subset không đổi — đó là fingerprint.
Code chỉ 1 dòng:
def fingerprint(alert: dict) -> str:
return f"{alert['service']}|{alert['metric']}|{alert['severity']}"
Field nào VÀO fingerprint?
| Field | Vào không? | Lý do |
|---|---|---|
| service, metric, severity | ✅ | Định danh “loại alert nào” — không đổi giữa các lần fire |
| timestamp, value | ❌ | Đổi mỗi lần fire — include thì 2 alert nào cũng khác fingerprint, dedup vô dụng |
| labels.host | ❌ | Trong K8s, 3 pod cùng service = 3 host khác — nhưng cùng vấn đề |
| labels.env | ⚠️ | Include nếu muốn phân biệt prod vs staging |
2.2 Dedup with state
Dedup cần state: 1 dictionary lưu fingerprint → cluster. Alert mới đến → check dict → update count hoặc tạo entry.
class Deduper:
def __init__(self):
self.store: dict[str, dict] = {}
def push(self, alert: dict) -> str:
fp = fingerprint(alert)
if fp not in self.store:
self.store[fp] = {
'cluster_id': fp,
'count': 1,
'first_seen': alert['ts'],
'last_seen': alert['ts'],
'alerts': [alert['id']],
}
else:
c = self.store[fp]
c['count'] += 1
c['last_seen'] = alert['ts']
c['alerts'].append(alert['id'])
return fp
⚠️ Cảnh báo về memory: self.store không có giới hạn — sau 24h trên production có 100k+ entries. Cần TTL eviction (xem §6.3).
2.3 Khi dedup không đủ
Dedup chỉ gom alert giống hệt nhau. Nó không gom được:
payment-svc latency+payment-svc error_rate(cùng service, khác metric)payment-svc+checkout-svc(khác service, cùng cause)
→ Cần thêm 2 layer nữa.
3. Layer 2 — Time-Window (gom alert gần nhau về thời gian)
3.1 Insight: thời gian là tín hiệu
Nếu 5 service cùng kêu trong 2 phút, khả năng chúng cùng cause là RẤT cao. Nếu spread ra 2 giờ, có thể chẳng liên quan.
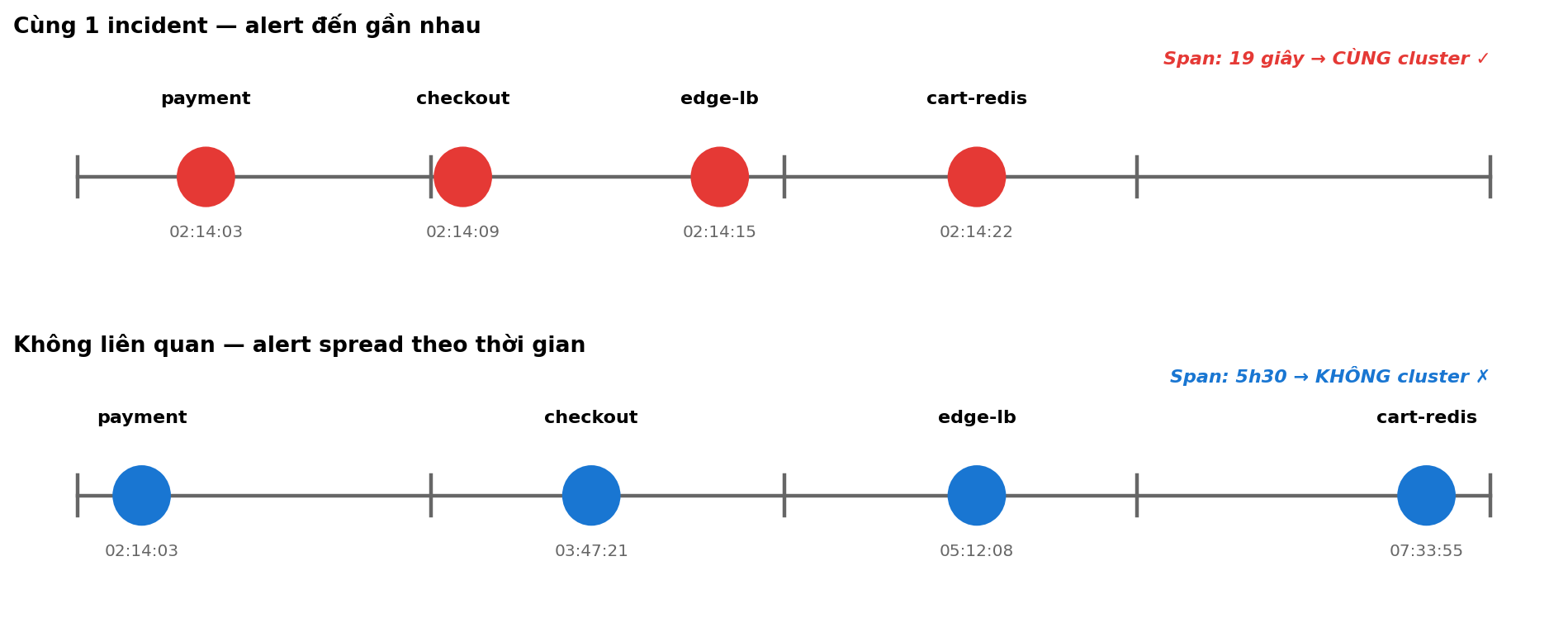
Layer này chỉ làm 1 việc: gom alert đến gần nhau về thời gian thành 1 nhóm.
3.2 Ba loại window
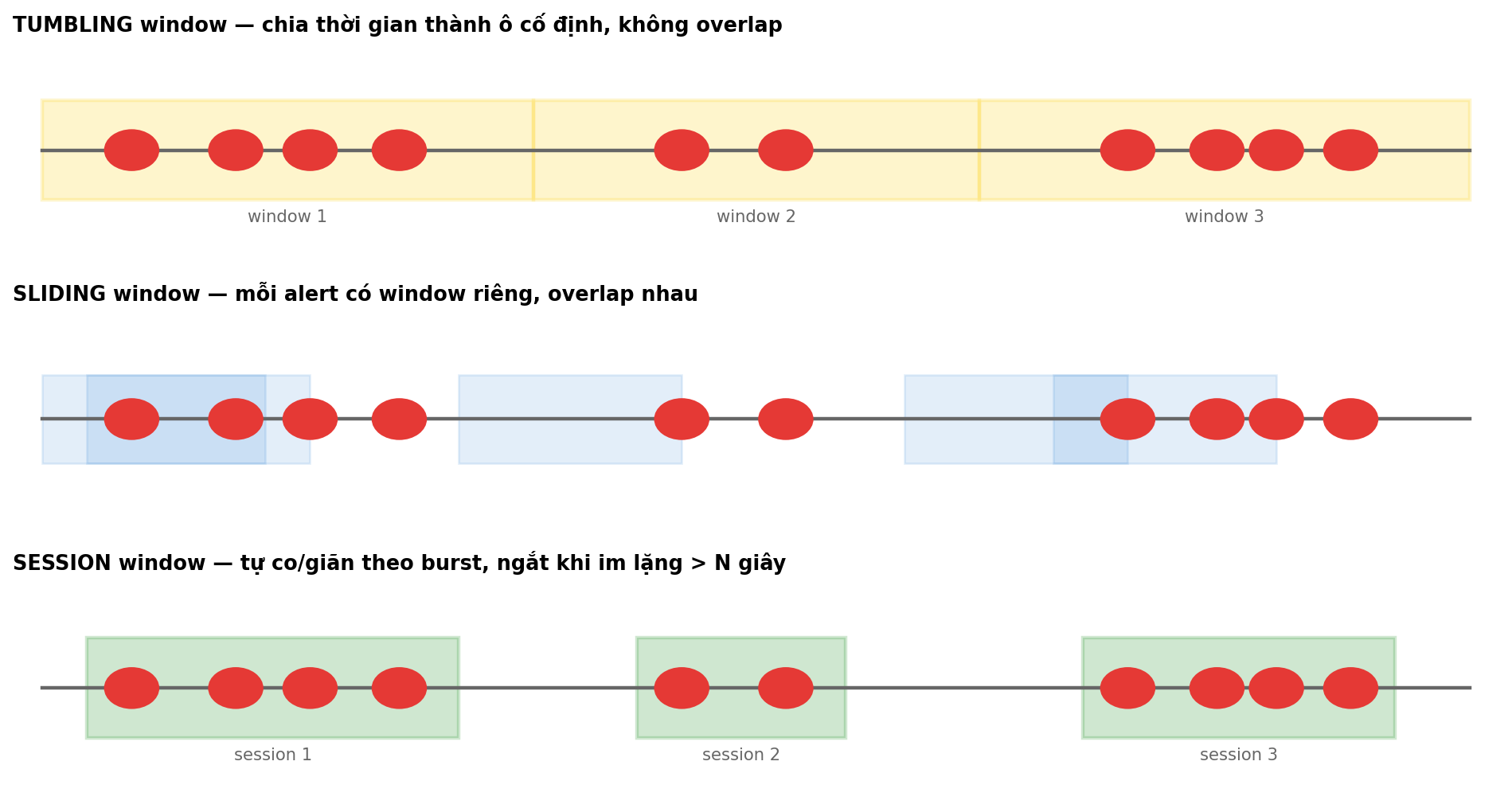
| Window | Mô tả | Ưu | Nhược |
|---|---|---|---|
| Tumbling | Chia thời gian thành ô cố định, không overlap | Đơn giản, mỗi alert thuộc đúng 1 window | Incident span ranh giới window → bị cắt thành 2 |
| Sliding | Mỗi alert có window backward riêng | Linh hoạt cho live alerting | Overlap nhiều — 1 alert nằm trong nhiều group |
| Session ⭐ | Tự co/giãn theo burst, ngắt khi im lặng > N giây | Adapt tốt với incident pattern | Cần tune gap_sec |
Trong bài này dùng session window — tự nhiên nhất cho incident.
def session_groups(alerts: list[dict], gap_sec: int = 120) -> list[list[dict]]:
"""Mỗi group là 1 'session'. Session ngắt khi gap > gap_sec giây."""
if not alerts:
return []
sorted_alerts = sorted(alerts, key=lambda a: a['ts'])
groups = [[sorted_alerts[0]]]
for alert in sorted_alerts[1:]:
last_ts = parse(groups[-1][-1]['ts'])
if (parse(alert['ts']) - last_ts).total_seconds() <= gap_sec:
groups[-1].append(alert)
else:
groups.append([alert])
return groups
3.3 Chọn gap_sec thế nào
gap_sec | Hậu quả |
|---|---|
| 30s | Group rất nhỏ. Incident dài bị tách |
| 120s (2 phút) ⭐ | Sweet spot cho hầu hết production |
| 300s (5 phút) | Group lớn hơn. Có thể merge 2 incident không liên quan |
| 600s+ | Bắt incident kéo dài. Cảnh giác false correlation |
💡 Tip production: Đo
gap_secbằng cách nhìn histogramtime_since_last_alert30 ngày qua. Chọn ở mức 95th percentile của intra-incident gap.
4. Layer 3 — Topology (gom alert theo cấu trúc service)
Time-window gom theo khi nào. Topology gom theo service nào nối với service nào.
4.1 Service graph là gì
Service graph là 1 đồ thị có hướng:
- Node = service
- Mũi tên A → B = service A gọi service B (A phụ thuộc vào B)
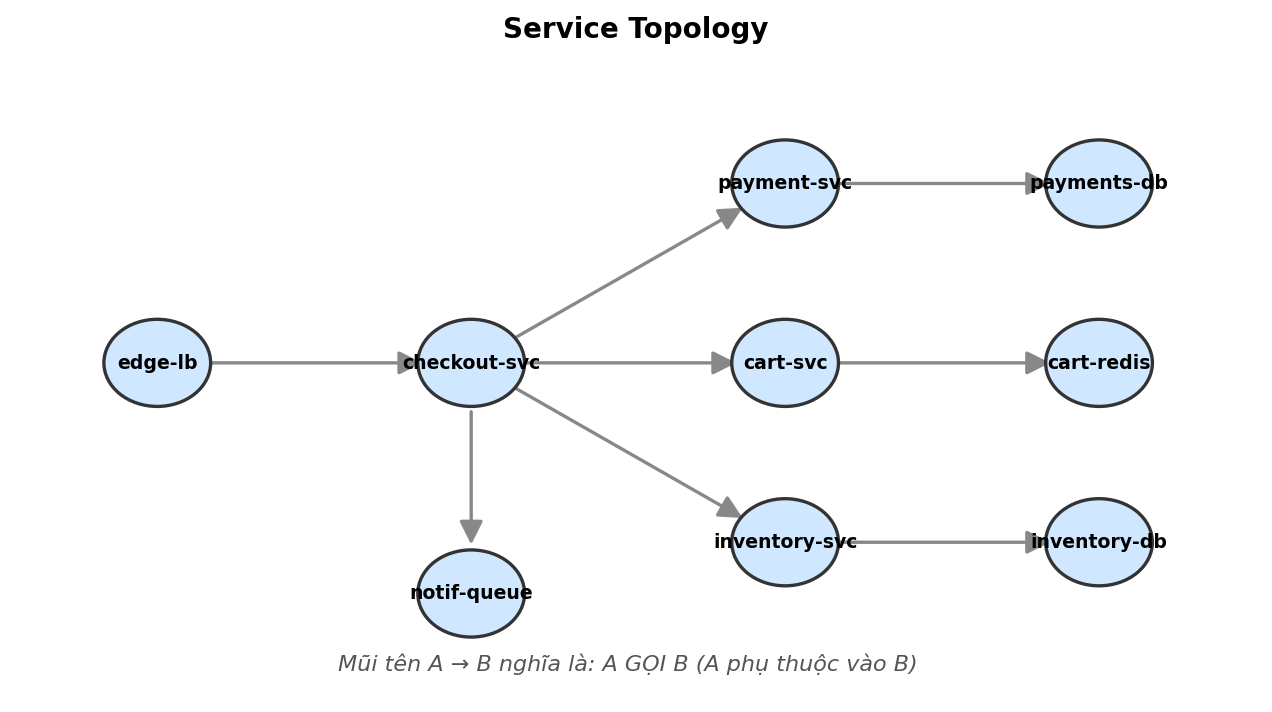
4.2 Lỗi lan như thế nào?
Câu hỏi quan trọng: khi payment-svc hỏng, ai bị ảnh hưởng?
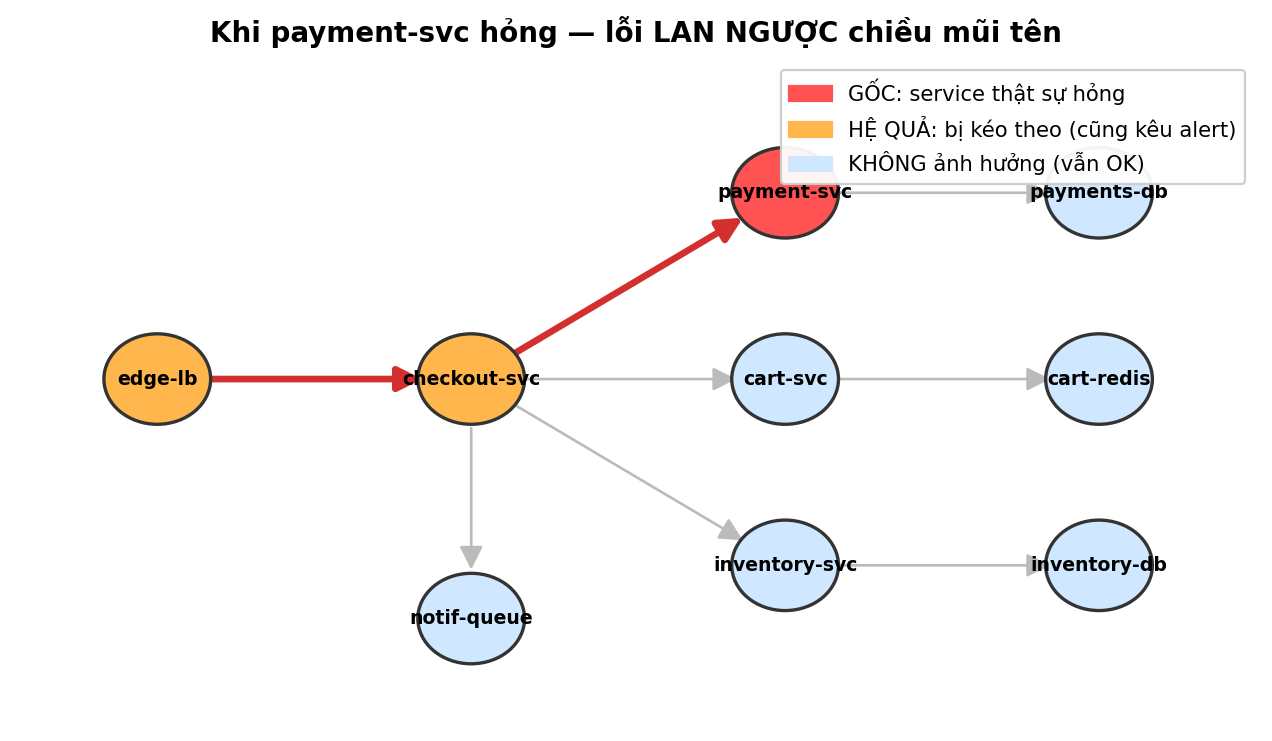
Đọc hình:
- 🔴 Đỏ =
payment-svc— service hỏng thật - 🟠 Cam =
checkout-svc+edge-lb— bị kéo theo. Tại sao? Chúng gọi vào payment-svc → khi payment chậm, chúng phải đợi → cũng chậm → cũng kêu alert - 🔵 Xanh =
payments-db,cart-svc,cart-redis,inventory-svc… — không liên quan. payments-db là cái payment-svc gọi xuống — nó vẫn OK
Quy luật đơn giản: Lỗi lan ngược chiều mũi tên — từ service hỏng → các service đang GỌI nó.
4.3 Gom alert theo topology
Cho 1 nhóm alert, gom chúng nếu service tương ứng “gần nhau” trên graph.
Cách phổ biến: 2 alert cùng cluster nếu khoảng cách ≤ max_hop (thường = 2) trên graph (bỏ chiều mũi tên khi tính khoảng cách — vì cascade có thể đi cả 2 phía tuỳ case).
import networkx as nx
from collections import defaultdict
def topology_group(alerts, graph, max_hop=2):
"""Gom alert có service cách nhau ≤ max_hop trên graph."""
undirected = graph.to_undirected()
by_service = defaultdict(list)
for a in alerts:
by_service[a['service']].append(a)
services = list(by_service.keys())
parent = {s: s for s in services}
def find(x):
while parent[x] != x:
parent[x] = parent[parent[x]]
x = parent[x]
return x
for i, s1 in enumerate(services):
for s2 in services[i+1:]:
try:
if nx.shortest_path_length(undirected, s1, s2) <= max_hop:
parent[find(s1)] = find(s2)
except nx.NetworkXNoPath:
pass
groups = defaultdict(list)
for s in services:
groups[find(s)].extend(by_service[s])
return list(groups.values())
4.4 Kết hợp Time-Window + Topology
Mỗi layer alone không đủ:
| Layer | Vấn đề khi dùng riêng |
|---|---|
| Time-window only | Recommender batch retrain + payment crash trùng giờ → gom nhầm |
| Topology only | 2 alert cùng cascade chain nhưng cách nhau 6 giờ → gom nhầm |
Combined logic: 2 alert cùng cluster nếu VỪA cùng time-window VỪA cùng topology component.
def correlate(alerts, graph, gap_sec=120, max_hop=2):
sessions = session_groups(alerts, gap_sec=gap_sec)
clusters = []
for s_idx, session_alerts in enumerate(sessions):
for g_idx, group in enumerate(topology_group(session_alerts, graph, max_hop)):
clusters.append({
'cluster_id': f'c-{s_idx:03d}-{g_idx:03d}',
'alert_count': len(group),
'services': sorted({a['service'] for a in group}),
'time_range': [min(a['ts'] for a in group), max(a['ts'] for a in group)],
'max_severity': max(a['severity'] for a in group),
'alert_ids': [a['id'] for a in group],
})
return clusters
5. Layer 4 (Bonus) — Semantic Similarity
Đôi khi 2 alert có fingerprint khác nhau nhưng cùng nói 1 chuyện:
payment-svc db_pool_used_ratio = 0.95(warn)payment-svc db_connection_count = 49 / 50(crit)
Cả 2 đo DB pool gần cạn — nhưng metric name khác → dedup miss.
Approach đơn giản: Jaccard similarity trên tokenized metric name.
def text_similarity(a, b) -> float:
def tokens(x):
text = f"{x['metric']} {x.get('labels', {}).get('note', '')}"
return set(text.lower().replace('_', ' ').split())
ta, tb = tokens(a), tokens(b)
return len(ta & tb) / len(ta | tb) if ta and tb else 0.0
Approach nâng cao: sentence-transformer encode → cosine similarity > 0.8 = semantically related.
Không bắt buộc cho bài tập. Đề cập để biết direction.
6. Production Patterns
6.1 Alertmanager (Prometheus ecosystem)
Alertmanager có routing tree + grouping rules built-in:
route:
group_by: ['alertname', 'cluster', 'service']
group_wait: 30s # Đợi 30s gom thêm alert giống nhau
group_interval: 5m # Gom alert vào group cũ trong 5 phút
repeat_interval: 4h # Re-fire group đã active sau 4h
Đây là dedup + time-window + simple grouping ở mức infrastructure. Không có topology — bạn phải tự build.
6.2 Vì sao cần layer riêng
Alertmanager grouping work ở mỗi route, không cross-route. Topology-aware correlation phải ở mức platform-wide. Đây là việc của alert correlator riêng — có sản phẩm thương mại (BigPanda, Moogsoft) nhưng cốt lõi không khác gì code bạn vừa viết.
6.3 Memory + TTL eviction
def evict_stale(store: dict, ttl_sec: int = 3600):
"""Xoá entries cũ. Gọi mỗi 5 phút bằng scheduler."""
now = datetime.now(timezone.utc)
stale = [k for k, v in store.items()
if (now - v['last_seen']).total_seconds() > ttl_sec]
for k in stale:
del store[k]
6.4 Flapping suppression
Alert “flap” = liên tục fire/clear (CPU dao động quanh 80%). Đếm số lần fire trong window:
def is_flapping(events: list[str], window: int = 10) -> bool:
"""events = ['fire', 'clear', 'fire', ...] in last 10 minutes."""
return events[-window:].count('fire') >= 5
7. Bài tập — Build correlator của bạn
Task: Code correlate.py cho dataset bên dưới.
Quy ước file path (pipeline downstream parse theo tên):
- Branch
main- Path:
aiops-<tên>/w2/d1/—w2vàd1đều lowercase- File:
assignment.ipynb+SUBMIT.md+results/cluster_summary.json- Sai naming → pipeline không tìm thấy file.
7.1 Tải dataset
- Alert sample (20 alert): alerts_sample.jsonl
- Service graph: services.json
Lưu vào aiops-<tên>/w2/d1/dataset/ (cùng folder với notebook).
7.2 Output
File results/cluster_summary.json theo format:
{
"input_alerts": 20,
"output_clusters": 3,
"reduction_ratio": 0.85,
"clusters": [
{
"cluster_id": "c-001-000",
"alert_count": 14,
"services": ["payment-svc", "checkout-svc", "edge-lb"],
"time_range": ["2026-06-12T09:42:01Z", "2026-06-12T09:48:30Z"],
"max_severity": "crit",
"fingerprints": ["payment-svc|latency_p99_ms|crit"]
}
]
}
7.3 Steps
- Tạo folder
aiops-<tên>/w2/d1/ - Tạo notebook
assignment.ipynb, import các function trong bài - Load
services.json+alerts_sample.jsonl - Chạy
correlate()pipeline - Ghi output vào
results/cluster_summary.json - Viết
SUBMIT.md≥ 100 từ, trả lời:- Bạn chọn
gap_secbao nhiêu, vì sao? - Bạn chọn
max_hopbao nhiêu, vì sao? - 1 alert ID đã bị “miss” (không match cluster nào) — tại sao?
- Nếu có 10000 alert thay vì 20, code của bạn sẽ chậm ở đâu?
- Bạn chọn
7.4 Acceptance criteria
- Notebook chạy được, có ≥ 3 cell có output
results/cluster_summary.jsonexist + valid JSON- Cluster có cả
serviceslist vàtime_range reduction_ratio = 1 - output_clusters / input_alerts≥ 0.5SUBMIT.md≥ 100 từ, có ít nhất 1 design trade-off thảo luận
8. EOD Checkpoint
Trả lời ngắn (~50-100 từ mỗi câu) trong SUBMIT.md:
- Vì sao fingerprint không include
timestamphayvalue? Cho ví dụ nếu include thì hệ thống behave ra sao. - Sự khác biệt giữa “duplicate” và “correlated” alert? Ví dụ cụ thể từ dataset.
gap_sec = 30vsgap_sec = 600— mỗi cái ảnh hưởng output thế nào? 1 dòng cho mỗi case.- Trong scenario chính (payment-svc pool exhaustion), recommender-svc cũng alert (batch retrain). Correlator của bạn có gom recommender vào cluster chính không? Vì sao có / không?
- Limitation lớn nhất của topology grouping mà bạn nhận ra? Đề xuất 1 cách khắc phục.
Câu 4 là câu “soul” của bài — trả lời được = bạn hiểu topology-aware correlation. Confused → đọc lại §4 + chạy với
alerts_sample.jsonlđể quan sát.
9. Tài liệu tham khảo
- Prometheus Alertmanager docs: https://prometheus.io/docs/alerting/latest/alertmanager/
- “You’re About To Get Paged” — Charity Majors blog series về alert fatigue
- BigPanda blog — case study correlation trong industry: https://www.bigpanda.io/blog/