W1-D1: Metric Anomaly Detection
Table of Contents
- Metric Anomaly Detection
- 1. Nền Tảng: Phân Phối Dữ Liệu & Tại Sao Nó Quan Trọng
- 2. Statistical Methods — Baseline
- 3. ML Methods — Khi Statistical Không Đủ
- 4. DL Methods — Biết Để Biết
- 5. Univariate vs Multivariate — Khi Nào Cần Nhìn Nhiều Metric Cùng Lúc
- 6. So Sánh Trực Quan
- 7. Chọn Phương Pháp
- 8. Feature Engineering cho Time Series
- 9. KPI Đo Lường
- References
- Assignment — Chiều Nay
Metric Anomaly Detection
Bạn có 1 microservice đang chạy production. Prometheus scrape metric mỗi 15 giây: CPU, memory, request latency p50/p95/p99, error rate, request throughput. Mọi thứ bình thường cho tới 2h sáng — latency p99 nhảy từ 200ms lên 1.2s, error rate từ 0.1% lên 4%, nhưng CPU và memory bình thường. On-call ngủ, PagerDuty chưa trigger vì threshold cứng đặt ở 5% error.
Anomaly detection tự động sẽ bắt được cái này sớm hơn threshold cứng 15-20 phút. Trong AIOps pipeline, đây là bước đầu tiên: phát hiện “cái lạ” trước khi nó trở thành outage.
Buổi hôm nay cover 3 tầng kỹ thuật từ đơn giản tới phức tạp. Rule: luôn bắt đầu từ đơn giản, chỉ lên DL khi đơn giản đã fail.
1. Nền Tảng: Phân Phối Dữ Liệu & Tại Sao Nó Quan Trọng
Trước khi nói về anomaly detection, cần hiểu data trông như thế nào. Hầu hết phương pháp statistical giả định data có phân phối chuẩn (Gaussian / normal distribution) — tức là data tập trung quanh giá trị trung bình, và giá trị càng xa trung bình thì càng hiếm.
Hình dưới minh hoạ 4 khái niệm nền tảng: phân phối chuẩn, skewness, stationarity, và tại sao 3σ fail trên skewed data.
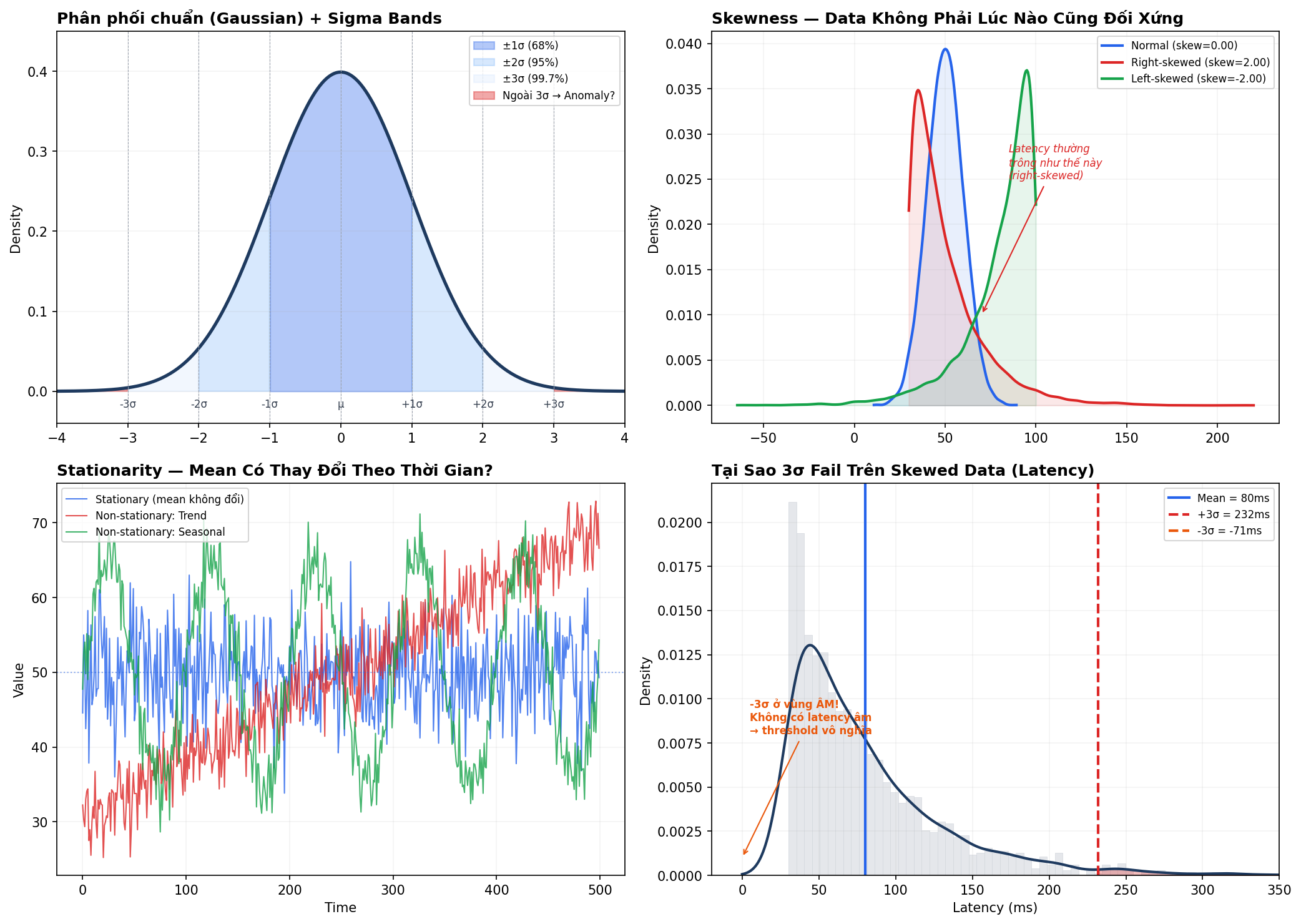
Phân phối chuẩn (Normal / Gaussian) — Hình trên trái
Hình dạng chuông (bell curve). Data tập trung quanh giá trị trung bình (mean, ký hiệu μ), và phân bổ đối xứng sang 2 bên. Đặc điểm quan trọng:
- ~68% data nằm trong ±1σ (1 standard deviation) quanh mean
- ~95% nằm trong ±2σ
- ~99.7% nằm trong ±3σ → cái gì ngoài 3σ (vùng đỏ trong hình) cực kỳ hiếm → có thể là anomaly
Standard deviation (σ) đo “data dao động bao nhiêu quanh mean”. σ nhỏ → data tập trung sát mean (bell curve nhọn). σ lớn → data phân tán rộng (bell curve phẳng).
VD cụ thể: CPU usage trung bình μ = 40%, σ = 10%.
- 68% thời gian CPU nằm trong 30%-50% (±1σ)
- 95% thời gian CPU nằm trong 20%-60% (±2σ)
- 99.7% thời gian CPU nằm trong 10%-70% (±3σ)
- Nếu CPU nhảy lên 85% → cách mean 4.5σ → xác suất xảy ra tự nhiên cực thấp → anomaly
Skewness — Khi Data Không Đối Xứng — Hình trên phải
Nhiều metric không có phân phối chuẩn. Ví dụ request latency: đa số request trả về trong 50-100ms, nhưng thỉnh thoảng có request 500ms-2s (do GC pause, cache miss, database slow query). Khi bạn vẽ histogram, data không đối xứng — nó bị “kéo” về 1 phía. Hiện tượng này gọi là skewness (độ lệch).
- Skewness ≈ 0: data đối xứng quanh mean (Gaussian). Ví dụ: CPU usage, temperature.
- Skewness > 0 (right-skewed / lệch phải): đa số giá trị tập trung bên trái, có đuôi dài bên phải. Ví dụ: latency, response time, file size, income.
- Skewness < 0 (left-skewed / lệch trái): đuôi dài bên trái. Ít gặp trong metric infra.
Trong hình trên phải, đường đỏ là latency — right-skewed rõ ràng. Đa số request nhanh (đỉnh bên trái), nhưng có đuôi dài bên phải (request chậm).
Cách kiểm tra:
from scipy import stats
skewness = stats.skew(data)
# |skewness| < 0.5 → gần Gaussian, dùng 3σ OK
# |skewness| 0.5-1 → moderate skew, cẩn thận với 3σ
# |skewness| > 1 → heavily skewed, KHÔNG dùng 3σ trực tiếp
Tại sao 3σ fail trên skewed data — Hình dưới phải
Xem hình dưới phải: data latency bị right-skewed. Khi tính mean và σ trên data này:
- Mean = 80ms (bị kéo lên bởi các giá trị lớn ở đuôi phải)
- -3σ = -71ms → giá trị ÂM! Không có latency âm trên đời. Threshold bên trái hoàn toàn vô nghĩa.
- +3σ = 230ms → quá xa. Latency 180ms rõ ràng bất thường nhưng vẫn dưới +3σ → 3σ miss.
Cách xử lý khi data bị skew:
- Log transform:
np.log1p(data)— biến đổi data: giá trị lớn bị “nén” lại, giá trị nhỏ bị “kéo” ra → data trở nên đối xứng hơn → dùng 3σ trên log-transformed data. Đây là cách đơn giản và hiệu quả nhất.log_data = np.log1p(data) # log(1 + x), tránh log(0) # Bây giờ tính 3σ trên log_data, kết quả tốt hơn nhiều - IQR (Interquartile Range): Không giả định Gaussian — dùng percentile thay vì mean/σ:IQR dùng median (giá trị giữa) thay vì mean → không bị ảnh hưởng bởi outlier ở đuôi.
Q1 = np.percentile(data, 25) # 25% data nhỏ hơn Q1 Q3 = np.percentile(data, 75) # 75% data nhỏ hơn Q3 IQR = Q3 - Q1 # khoảng chứa 50% data ở giữa lower = Q1 - 1.5 * IQR upper = Q3 + 1.5 * IQR anomalies = (data < lower) | (data > upper) - Dùng Isolation Forest: không quan tâm distribution gì hết — sẽ học ở phần sau.
Stationarity — Data Có Thay Đổi Theo Thời Gian Không? — Hình dưới trái
Xem hình dưới trái:
- Xanh dương (stationary): mean không đổi theo thời gian, dao động quanh 50 liên tục. 3σ hoạt động tốt vì mean và σ ổn định.
- Đỏ (trend): mean tăng dần. Nếu tính mean trên toàn bộ data, nó sẽ ở giữa (~45) — nhưng data đầu ở 30, data cuối ở 70. Data đầu sẽ bị gọi “thấp bất thường”, data cuối bị gọi “cao bất thường”. Cả 2 đều sai.
- Xanh lá (seasonal): pattern lặp lại (lên xuống đều đặn). 3σ trên toàn bộ data sẽ false alarm ở đỉnh và đáy seasonal vì chúng xa mean tổng.
Tại sao quan trọng: Nếu data non-stationary mà bạn tính mean + std trên toàn bộ data → mean và std sai → threshold sai → false alarm hoặc miss anomaly. Cần:
- Tách trend + seasonal ra trước (STL decomposition — section 2.3)
- Hoặc dùng rolling window (tính mean/std trên N điểm gần nhất thay vì toàn bộ)
2. Statistical Methods — Baseline
2.1 Z-Score (3-Sigma Rule)
Bài toán: Bạn cần 1 cách đơn giản nhất có thể để tự động phát hiện “giá trị lạ” trên 1 metric. Không cần train model, không cần data label, chạy được real-time, implement trong 10 phút.
Ý tưởng: Tính mean (μ) và standard deviation (σ) trên data gần đây. Nếu 1 data point mới cách mean hơn 3σ → nó nằm ngoài vùng 99.7% → rất khó xảy ra tự nhiên → có thể là anomaly.
Z-score cho biết data point cách mean bao nhiêu standard deviation:
$$z = \frac{x - \mu}{\sigma}$$
Ví dụ: CPU mean = 40%, σ = 10%.
- CPU = 55% → z = (55-40)/10 = 1.5 → cách mean 1.5σ → bình thường (nằm trong ±2σ)
- CPU = 85% → z = (85-40)/10 = 4.5 → cách mean 4.5σ → anomaly (ngoài ±3σ)
Tại sao dùng rolling window thay vì tính trên toàn bộ data:
Nếu tính μ và σ trên toàn bộ lịch sử (VD: 30 ngày data), bạn gặp 2 vấn đề:
- Data cũ outdated: System upgrade tuần trước làm CPU baseline từ 30% lên 50%. Data cũ kéo mean xuống → data mới bị gọi anomaly vì mean sai.
- Seasonal bị trộn: Traffic ban ngày cao, ban đêm thấp. Mean của 30 ngày = trung bình ngày+đêm → ban ngày nào cũng “cao bất thường”, ban đêm nào cũng “thấp bất thường”.
Rolling window giải quyết bằng cách chỉ nhìn N điểm gần nhất. VD: window = 60 phút → chỉ tính mean và std trên 60 data points gần nhất → phản ánh “bình thường” tại thời điểm hiện tại.
import numpy as np
import pandas as pd
def detect_zscore(series, window=60, threshold=3.0):
"""
Detect anomalies using rolling Z-score.
Tính mean và std trên N data points gần nhất (rolling window).
Nếu |z-score| > threshold → anomaly.
Args:
series: numpy array hoặc pandas Series — metric values theo thời gian
window: int — số data points để tính mean/std
VD: data mỗi 1 phút → window=60 = nhìn 1 giờ gần nhất
VD: data mỗi 5 phút → window=12 = nhìn 1 giờ gần nhất
threshold: float — ngưỡng z-score (thường = 3, có thể 2.5 nếu muốn nhạy hơn)
Returns:
boolean array — True = anomaly, False = normal
"""
s = pd.Series(series)
rolling_mean = s.rolling(window=window, min_periods=1).mean()
rolling_std = s.rolling(window=window, min_periods=1).std()
# Tránh chia cho 0: khi data hoàn toàn phẳng (std = 0),
# set std = giá trị rất nhỏ để z-score = 0 (bình thường)
rolling_std = rolling_std.replace(0, 1e-10)
z_scores = (s - rolling_mean) / rolling_std
return np.abs(z_scores) > threshold
Ví dụ minh hoạ bằng số:
Giả sử memory usage (%), window = 5:
| t | Value | Rolling Mean (5) | Rolling Std | Z-score | Anomaly? |
|---|---|---|---|---|---|
| 1 | 40 | 40.0 | - | 0.0 | No |
| 2 | 42 | 41.0 | 1.41 | 0.71 | No |
| 3 | 38 | 40.0 | 2.00 | -1.00 | No |
| 4 | 41 | 40.25 | 1.71 | 0.44 | No |
| 5 | 39 | 40.0 | 1.58 | -0.63 | No |
| 6 | 43 | 40.6 | 1.95 | 1.23 | No |
| 7 | 75 | 40.2 | 1.92 | 18.1 | YES |
| 8 | 41 | 47.2 | 14.9 | -0.42 | No |
Ở t=7, memory nhảy lên 75% → z-score = 18.1 → rõ ràng anomaly. Nhưng chú ý t=8: sau anomaly, rolling mean bị kéo lên 47.2 và rolling std bị bung rộng → dễ miss anomaly tiếp theo. Đây là nhược điểm của rolling window — outlier làm “ô nhiễm” window.
Cách giải: dùng rolling median thay mean (robust hơn với outlier), hoặc dùng STL decomposition (section 2.3).
| Ưu | Nhược |
|---|---|
| Cực nhanh, O(n), chạy real-time trên hàng triệu data points | Giả định data gần Gaussian — sai với latency (skewed) |
| Implement 10 dòng code, dễ explain cho ops team | Không handle seasonal pattern (traffic ngày/đêm) |
| Không cần training data, không cần label | Window size phải tune manual cho từng metric |
| Deterministic — cùng input luôn cho cùng output | Outlier “ô nhiễm” window → miss anomaly liên tiếp |
Khi nào dùng: Metric ổn định, không seasonal, gần Gaussian — disk usage, memory usage, connection pool size, queue depth, CPU (nếu workload đều).
Common mistake: Dùng 3σ trên request latency. Latency thường right-skewed (đa số request nhanh 50ms, vài cái chậm 500ms). 3σ tính trên data skewed → threshold bên phải quá xa (xem hình distribution-basics panel dưới phải) → miss anomaly thật. Cách fix: log transform trước (np.log1p(latency)), hoặc chuyển sang IQR, hoặc dùng Isolation Forest.
Tuning window size:
Window quá nhỏ vs quá lớn có trade-off rõ ràng:
| Window | Ưu | Nhược | Dùng khi |
|---|---|---|---|
| 10-30 | Detect nhanh, nhạy | Nhiều false alarm, noisy | Metric ít noise (disk usage) |
| 60-120 | Balance tốt | Miss trend chậm | Hầu hết metric (default) |
| 240-1440 | Ổn định, ít false alarm | Chậm detect, miss spike ngắn | Metric biến động tự nhiên |
Rule of thumb: window = 1-2 giờ data là starting point tốt. Tune lên/xuống theo false alarm rate.
2.2 EWMA (Exponentially Weighted Moving Average)
Bài toán: Bạn có 1 service mà memory cứ tăng dần 50MB mỗi giờ. Giờ 1: 2.0 GB, giờ 2: 2.05 GB, giờ 3: 2.1 GB… Mỗi điểm chỉ tăng 50MB — quá nhỏ so với rolling window 1 giờ. 3σ sẽ không bao giờ trigger vì mỗi data point riêng lẻ nằm thoải mái trong band. Nhưng sau 20 giờ, memory đã ở 3.0 GB và sắp OOM.
Đây là bài toán trend detection — phát hiện thay đổi dần dần mà mỗi bước riêng lẻ quá nhỏ để trigger anomaly.
Ý tưởng EWMA: Thay vì tính trung bình đều (mỗi điểm trong window có cùng weight), cho data gần đây weight lớn hơn và data cũ weight nhỏ hơn — nhưng data cũ không bao giờ bị bỏ hẳn. Điều này tạo ra 1 “trí nhớ dài hạn”: EWMA nhớ rằng hồi đầu memory là 2.0 GB, nên khi memory lên 2.5 GB, nó biết đã drift xa.
Công thức:
$$\text{EWMA}t = \alpha \cdot x_t + (1 - \alpha) \cdot \text{EWMA}{t-1}$$
Đọc thế này: giá trị EWMA tại thời điểm t = α% giá trị mới + (1-α)% giá trị EWMA cũ.
α (alpha) là smoothing factor — quyết định “nhớ bao xa”:
Hãy tưởng tượng bạn đang lái xe và liên tục nhìn đồng hồ tốc độ. α quyết định bạn tin tốc độ hiện tại bao nhiêu so với “cảm giác tốc độ” tích lũy:
- α = 0.9 (tin hiện tại 90%): bạn gần như chỉ tin con số hiện tại trên đồng hồ. Phản ứng cực nhanh — 1 cú tăng tốc bạn biết ngay. Nhưng cũng nhạy với nhiễu — bump trên đường làm kim đồng hồ giật, bạn tưởng đang tăng tốc.
- α = 0.1 (tin hiện tại 10%): bạn “nhớ” tốc độ trung bình cả chuyến đi. Nếu đã chạy 60 km/h suốt 1 giờ rồi đột nhiên tăng lên 80 km/h, EWMA chỉ nhích lên chút — không hoảng vì 1 data point. Nhưng nếu tốc độ cứ tăng dần 60 → 65 → 70 → 75 → 80 trong 30 phút, EWMA sẽ bắt được trend này.
- α = 0.3: balance tốt cho hầu hết use case.
Tại sao Rolling Mean (3σ) miss mà EWMA bắt được:
Rolling mean với window = 60 tính trung bình 60 điểm gần nhất. Khi data drift dần, cả 60 điểm đều drift theo → mean drift theo → band drift theo → data mới luôn nằm trong band. Rolling mean “quên” hết data trước window — nó không biết rằng 3 giờ trước, memory chỉ 2.0 GB.
EWMA thì khác: data cũ vẫn có weight (nhỏ nhưng khác 0). Data 3 giờ trước vẫn ảnh hưởng (dù rất ít) tới EWMA hiện tại. Nên khi data drift từ 2.0 lên 2.5, EWMA vẫn “nhớ” rằng bình thường là 2.0-2.1, và 2.5 đã khá xa so với expected.
Ví dụ minh hoạ bằng số:
| Giờ | Memory (GB) | Rolling Mean (w=4) | EWMA (α=0.1) | Deviation từ EWMA |
|---|---|---|---|---|
| 1 | 2.00 | - | 2.00 | 0.00 |
| 2 | 2.05 | - | 2.005 | 0.045 |
| 3 | 2.10 | - | 2.015 | 0.085 |
| 4 | 2.15 | 2.075 | 2.028 | 0.122 |
| 5 | 2.20 | 2.125 | 2.045 | 0.155 |
| 6 | 2.30 | 2.188 | 2.071 | 0.229 |
| 8 | 2.50 | 2.375 | 2.136 | 0.364 |
| 12 | 3.00 | 2.875 | 2.351 | 0.649 ← EWMA biết xa rồi |
| 16 | 3.50 | 3.375 | 2.647 | 0.853 |
Quan sát:
- Rolling mean (cột 3) drift theo data — ở giờ 12, rolling mean = 2.875, data = 3.0, chênh lệch chỉ 0.125 → 3σ sẽ nói “bình thường”
- EWMA (cột 4) nhớ xa hơn — ở giờ 12, EWMA = 2.351, data = 3.0, chênh lệch 0.649 → đủ lớn để trigger alert
import pandas as pd
import numpy as np
def detect_ewma(series, alpha=0.3, threshold=3.0):
"""
Detect anomalies using EWMA + deviation threshold.
So sánh giá trị thực vs EWMA prediction. Nếu chênh lệch
vượt quá threshold * EWMA std → anomaly.
Args:
series: metric values (array hoặc pd.Series)
alpha: smoothing factor
- 0.1: nhớ rất xa, detect trend chậm, ít false alarm
- 0.3: balance (default tốt)
- 0.9: phản ứng nhanh, nhiều noise
threshold: bao nhiêu std deviation thì coi là anomaly (thường = 3)
Returns:
boolean array — True = anomaly
"""
s = pd.Series(series)
ewma = s.ewm(alpha=alpha).mean() # predicted value
ewma_std = s.ewm(alpha=alpha).std() # expected volatility
ewma_std = ewma_std.replace(0, 1e-10) # tránh chia 0
deviation = np.abs(s - ewma) / ewma_std
return deviation > threshold
Tuning α — chọn theo use case:
| Use case | α | Lý do |
|---|---|---|
| Memory leak detection | 0.05-0.1 | Cần nhớ rất xa để thấy drift chậm |
| Latency degradation | 0.2-0.3 | Balance giữa detect drift và react spike |
| Sudden spike detection | 0.5-0.9 | Dùng 3σ sẽ tốt hơn, nhưng nếu muốn EWMA thì α cao |
| Capacity planning | 0.01-0.05 | Nhìn trend dài hạn (tuần/tháng) |
Common mistake: Dùng EWMA (α = 0.3) rồi phàn nàn nó detect chậm. α = 0.3 cần ~10 data points liên tục deviate mới trigger. Nếu cần detect spike nhanh → dùng 3σ, không phải EWMA. EWMA sinh ra để detect drift, không phải spike.
Khi nào dùng: Detect trend shift chậm — memory leak, disk filling, gradual performance degradation, connection pool exhaustion. 3σ miss vì rolling mean drift theo data, nhưng EWMA nhớ xa hơn.
2.3 STL Decomposition (Seasonal-Trend-Loess)
Bài toán: Web service có traffic cao ban ngày (8h-22h), thấp ban đêm (22h-8h). Mỗi ngày traffic peak lúc 12h trưa và 20h tối. Nếu dùng 3σ trên raw data:
- Ban đêm 2h sáng, traffic thấp → 3σ gọi “anomaly” vì thấp hơn mean cả ngày → false alarm
- Ban ngày 12h trưa, traffic hike → 3σ gọi “anomaly” vì cao hơn mean cả ngày → false alarm
- Nhưng lúc 12h trưa traffic thấp hơn mọi ngày trước đó → 3σ vẫn nói “OK” vì vẫn trên mean → miss anomaly thật
Vấn đề: 3σ không biết “12h trưa lẽ ra traffic phải cao” vs “2h sáng traffic thấp là bình thường”. Nó chỉ biết mean tổng.
Ý tưởng STL: Tách time series thành 3 thành phần riêng biệt, mỗi thành phần giải thích 1 khía cạnh khác nhau:
$$Y(t) = Trend(t) + Seasonal(t) + Residual(t)$$
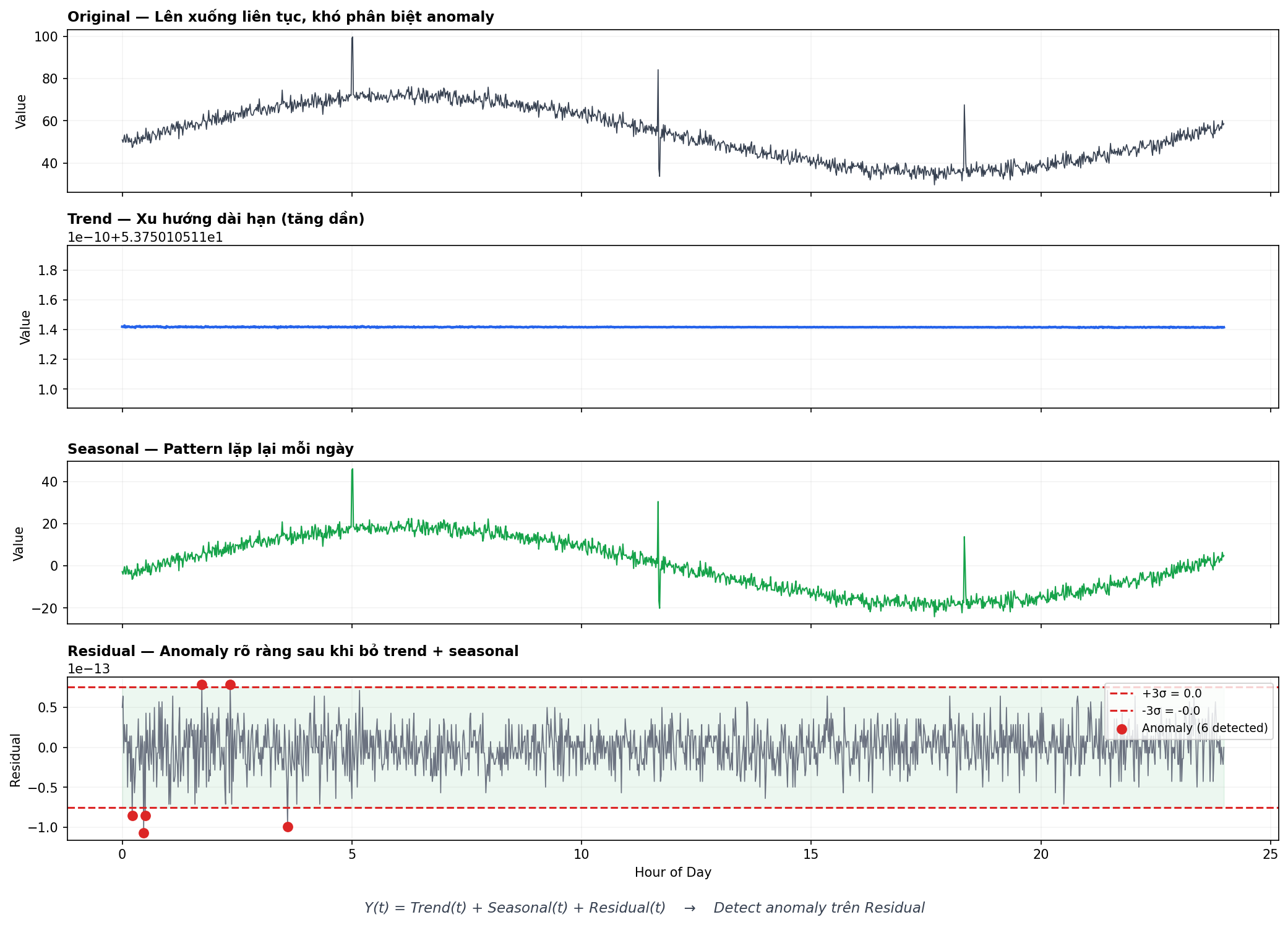
- Trend (panel 2): xu hướng dài hạn — traffic tổng thể tăng dần theo tháng, hoặc giảm sau campaign kết thúc. Thay đổi chậm, smooth.
- Seasonal (panel 3): pattern lặp lại với chu kỳ cố định — traffic cao ban ngày, thấp ban đêm, mỗi ngày giống nhau. Chu kỳ = 1 ngày (1440 phút nếu data 1-minute).
- Residual (panel 4): phần còn lại sau khi bỏ trend và seasonal. Nếu trend giải thích đúng xu hướng, seasonal giải thích đúng pattern lặp → residual chỉ còn noise ngẫu nhiên + anomaly. Detect anomaly trên residual rõ ràng hơn nhiều vì seasonal false alarm đã bị loại bỏ.
Xem panel 4 trong hình: anomaly (chấm đỏ) hiện ra rõ ràng trên nền residual phẳng, trong khi ở panel 1 (original) chúng lẫn trong seasonal pattern.
Loess là gì trong STL: STL viết tắt “Seasonal and Trend decomposition using Loess”. Loess (LOcally Estimated Scatterplot Smoothing) là kỹ thuật fitting: thay vì fit 1 đường thẳng toàn bộ data, nó fit nhiều đường cong ngắn trên từng vùng cục bộ → tạo ra 1 đường smooth mượt mà theo data. Bạn không cần implement Loess — statsmodels lo hết, chỉ cần chọn đúng period.
from statsmodels.tsa.seasonal import STL
import numpy as np
def detect_stl(series, period=1440, threshold=3.0):
"""
Detect anomalies using STL decomposition.
Tách time series → trend + seasonal + residual.
Detect anomaly trên residual bằng 3σ.
Args:
series: array-like — metric values theo thời gian
period: int — chu kỳ seasonal
Cách tính: bao nhiêu data points = 1 chu kỳ
- Data 1-minute, daily pattern: period = 1440 (60*24)
- Data 5-minute, daily pattern: period = 288 (60/5*24)
- Data 1-hour, daily pattern: period = 24
- Data 1-minute, weekly pattern: period = 10080 (1440*7)
threshold: float — ngưỡng sigma trên residual
Returns:
anomalies: boolean array
result: STL result object (dùng để plot trend/seasonal/residual)
"""
stl = STL(series, period=period, robust=True)
result = stl.fit()
residual = result.resid
resid_mean = np.mean(residual)
resid_std = np.std(residual)
anomalies = np.abs(residual - resid_mean) > threshold * resid_std
return anomalies, result
Tại sao robust=True: STL mặc định dùng least squares để fit trend + seasonal → outlier (anomaly) ảnh hưởng mạnh tới fitting → trend bị kéo về phía outlier → residual bị giảm → anomaly bị “giấu” trong residual. robust=True dùng iterative reweighting: sau lần fit đầu, những điểm có residual lớn (likely outlier) bị giảm weight → fit lần 2 bỏ qua chúng → anomaly giữ nguyên trong residual. Luôn dùng robust=True cho anomaly detection.
Chọn period đúng cách:
Period sai → STL decompose sai → toàn bộ kết quả sai. Đây là parameter quan trọng nhất.
| Granularity data | Period cho daily | Period cho weekly |
|---|---|---|
| 1 second | 86400 | Quá lớn, dùng daily |
| 1 minute | 1440 | 10080 |
| 5 minute | 288 | 2016 |
| 15 minute | 96 | 672 |
| 1 hour | 24 | 168 |
Cách verify period đúng — dùng ACF (Autocorrelation Function):
ACF đo “data giống chính nó bao nhiêu ở khoảng cách N bước”. Nếu data có daily pattern, ACF sẽ peak ở lag = 1 ngày data points.
from statsmodels.graphics.tsaplots import plot_acf
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(12, 4))
plot_acf(series, lags=3000, ax=ax)
plt.show()
# Peak đầu tiên (sau lag=0) = period
# VD: data 1-minute, peak ở lag 1440 → period = 1440 (daily pattern) ✓
# VD: data 1-minute, peak ở lag 10080 → period = 10080 (weekly pattern)
Common mistake: Data 5-minute mà đặt period=1440. 1440 là period cho data 1-minute (1440 phút = 1 ngày). Với data 5-minute, 1 ngày = 288 data points, nên period phải = 288. STL sẽ không error — nó sẽ chạy tốt nhưng decompose hoàn toàn sai → seasonal component bậy → residual bậy → miss anomaly và sinh false alarm. Luôn kiểm tra: period = số data points trong 1 chu kỳ seasonal, không phải số phút.
Khi nào dùng: Metric có daily/weekly pattern rõ ràng — request throughput, API latency (cao ngày, thấp đêm), CPU (cao business hours, thấp off-hours). Đây là default choice cho hầu hết metric infra trong production.
3. ML Methods — Khi Statistical Không Đủ
3.1 Isolation Forest
Bài toán: Bạn có 5 metric cùng lúc: CPU, memory, latency p99, error rate, throughput. Mỗi metric riêng lẻ bình thường, nhưng combination bất thường: CPU bình thường (35%), memory bình thường (60%), nhưng latency tăng + error tăng + throughput giảm cùng lúc. Statistical methods (3σ, STL) chỉ nhìn 1 metric tại 1 thời điểm → miss hoàn toàn.
Bạn cần model nhìn nhiều metric đồng thời và phát hiện khi combination bất thường.
Ý tưởng cốt lõi: Anomaly là điểm “dễ tách” khỏi đám đông.
Tưởng tượng bạn có 1000 data points trên mặt phẳng 2D (VD: trục X = CPU, trục Y = latency). 990 điểm tụ thành 1 đám (CPU 30-50%, latency 50-150ms). 10 điểm nằm rải rác ở xa (CPU 30% nhưng latency 500ms). Bây giờ, bạn random chọn 1 feature (CPU hoặc latency), random chọn 1 giá trị split → chia data thành 2 phần. Lặp lại cho tới khi mỗi điểm bị isolate (tách riêng).
Kết quả:
- Điểm bình thường (trong đám đông): cần nhiều lần split mới bị tách → path dài (5+ splits)
- Điểm anomaly (nằm xa): chỉ cần 1-2 lần split → path ngắn
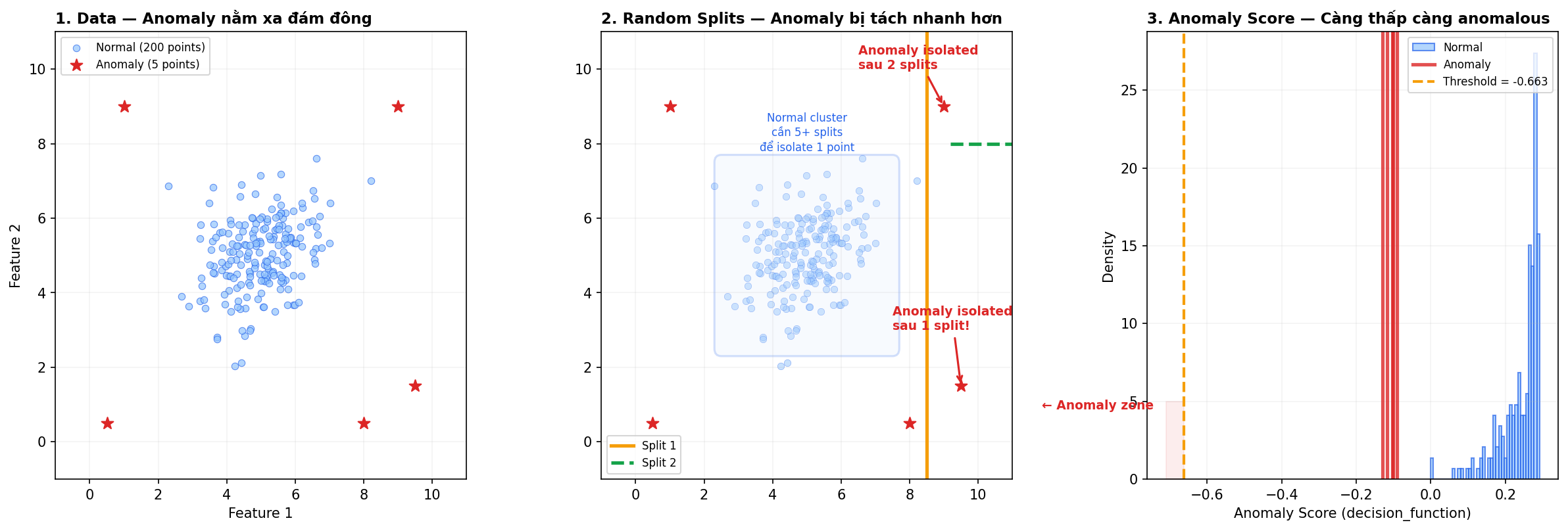
Xem hình: panel 1 là data (200 normal points xanh + 5 anomaly đỏ). Panel 2 cho thấy anomaly ở góc bị isolate sau 1-2 splits, trong khi normal cluster cần 5+ splits. Panel 3 là anomaly score distribution — anomaly có score thấp hơn rõ ràng, dễ dàng tách bằng threshold.
Anomaly score = average path length across all trees. Path ngắn → score thấp → anomaly.
Tại sao phải tạo feature trước khi feed vào Isolation Forest:
Isolation Forest xem mỗi row (data point) độc lập — nó không biết “data point trước là gì”. Nếu feed raw value [40, 42, 41, 43, 80], IF chỉ biết 80 khác với đám 40-43. Nhưng nó không biết rằng:
[40, 42, 41, 43, 80]→ spike đột ngột (anomaly)[40, 50, 60, 70, 80]→ tăng đều (có thể bình thường)
Cả 2 đều có giá trị 80 ở cuối, nhưng context khác nhau hoàn toàn. Để IF hiểu context, bạn cần biến time series thành feature table — mỗi row không chỉ có value, mà còn có rolling mean, rolling std, rate of change, lag… Các feature này mang context temporal vào model.
from sklearn.ensemble import IsolationForest
import pandas as pd
import numpy as np
def create_features(series, window=60):
"""
Biến 1 time series thành feature table cho Isolation Forest.
Mỗi row sẽ có 7 features: value hiện tại + 6 context features.
IF sẽ detect khi combination of features bất thường.
"""
s = pd.Series(series)
features = pd.DataFrame({
'value': s,
'rolling_mean_1h': s.rolling(window).mean(),
'rolling_std_1h': s.rolling(window).std(),
'rate_of_change': s.diff(), # tăng/giảm bao nhiêu so với point trước
'rate_of_change_5m': s.diff(5), # tăng/giảm so với 5 phút trước
'lag_1': s.shift(1), # value 1 phút trước
'lag_60': s.shift(window), # value 1 giờ trước
})
return features.dropna()
# ===== SINGLE METRIC (univariate) =====
series = np.array([...]) # metric values
X = create_features(series)
clf = IsolationForest(
n_estimators=200, # số cây — nhiều hơn = ổn định hơn, chậm hơn
contamination=0.02, # ước lượng 2% data là anomaly
max_features=1.0, # dùng hết feature
random_state=42, # reproducible
)
clf.fit(X)
labels = clf.predict(X) # -1 = anomaly, 1 = normal
scores = clf.decision_function(X) # càng âm càng anomalous
# ===== NHIỀU METRIC (multivariate) =====
# Feed nhiều metric cùng lúc — detect khi COMBINATION bất thường
X_multi = np.column_stack([cpu, memory, latency_p99, error_rate, throughput])
clf_multi = IsolationForest(contamination=0.02, random_state=42)
clf_multi.fit(X_multi)
labels_multi = clf_multi.predict(X_multi)
Tuning parameters:
| Parameter | Range | Trade-off | Recommendation |
|---|---|---|---|
n_estimators | 100-500 | Nhiều cây = ổn định hơn + chậm hơn | 200 đủ cho hầu hết case |
contamination | 0.005-0.1 | Thấp = ít anomaly detected, Cao = nhiều false alarm | Bắt đầu 0.01-0.02, tune theo false alarm rate |
max_samples | 256-1024 | Nhỏ = nhanh + ít accurate | Default 256 OK cho data < 100k |
max_features | 0.5-1.0 | < 1.0 = đa dạng hơn giữa các cây | 1.0 nếu ít feature (< 10) |
Cách tune contamination: Bắt đầu 0.01 (1% anomaly). Chạy trên data lịch sử, đếm số alert → nếu quá nhiều false alarm → giảm xuống 0.005. Nếu miss anomaly đã biết → tăng lên 0.03-0.05.
Common mistake: Feed raw time series vào Isolation Forest mà không tạo feature. IF xem mỗi row độc lập — data point có value 80 có thể bình thường (nếu trước đó là 75, 78, 79) hoặc anomaly (nếu trước đó là 30, 32, 31). Luôn tạo rolling features trước — ít nhất: rolling mean, rolling std, rate of change.
Khi nào dùng:
- Multivariate anomaly (nhiều metric cùng lúc) — đây là killer feature của IF
- Data không có label (unsupervised) — hầu hết metric data không có label
- Data bị skew (IF không giả định distribution)
- Data lớn (IF nhanh: O(n log n))
3.2 One-Class SVM
Train boundary quanh data “bình thường”. Mọi thứ ngoài boundary = anomaly. Khác IF ở chỗ cần data sạch (chỉ normal) để train — IF train trên cả normal + anomaly.
from sklearn.svm import OneClassSVM
clf = OneClassSVM(kernel='rbf', nu=0.02, gamma='scale')
clf.fit(X_normal) # chỉ train trên data bình thường!
labels = clf.predict(X_test) # -1 = anomaly
So sánh trực tiếp:
| Isolation Forest | One-Class SVM | |
|---|---|---|
| Speed | O(n log n) — nhanh | O(n²) tới O(n³) — rất chậm |
| Data size | Hàng triệu rows OK | > 50k rows bắt đầu chậm đáng kể |
| Training data | Train trên cả normal + anomaly | Cần data “sạch” chỉ có normal |
| Hyperparameters | contamination (1 param) | kernel, nu, gamma (3 params, khó tune) |
| Interpretability | Anomaly score trực quan | Decision boundary khó visualize > 3D |
Kết luận thực tế: Trong AIOps production, Isolation Forest thắng gần như mọi lúc vì nhanh hơn 10-100x, ít tune hơn, không cần data sạch. One-Class SVM chỉ dùng khi data rất nhỏ (< 10k points) và bạn có data sạch đảm bảo chỉ normal.
4. DL Methods — Biết Để Biết
Phần này để hiểu landscape, không cần implement hôm nay. Trong production AIOps, < 20% team dùng DL cho anomaly detection — STL + Isolation Forest cover 80% use case.
4.1 Autoencoder
Neural network học nén (encode) data vào không gian nhỏ hơn rồi giải nén (decode) lại. Train trên data bình thường → model học “pattern bình thường trông như thế nào”. Khi gặp anomaly (pattern chưa từng thấy) → decode sai → reconstruction error cao.
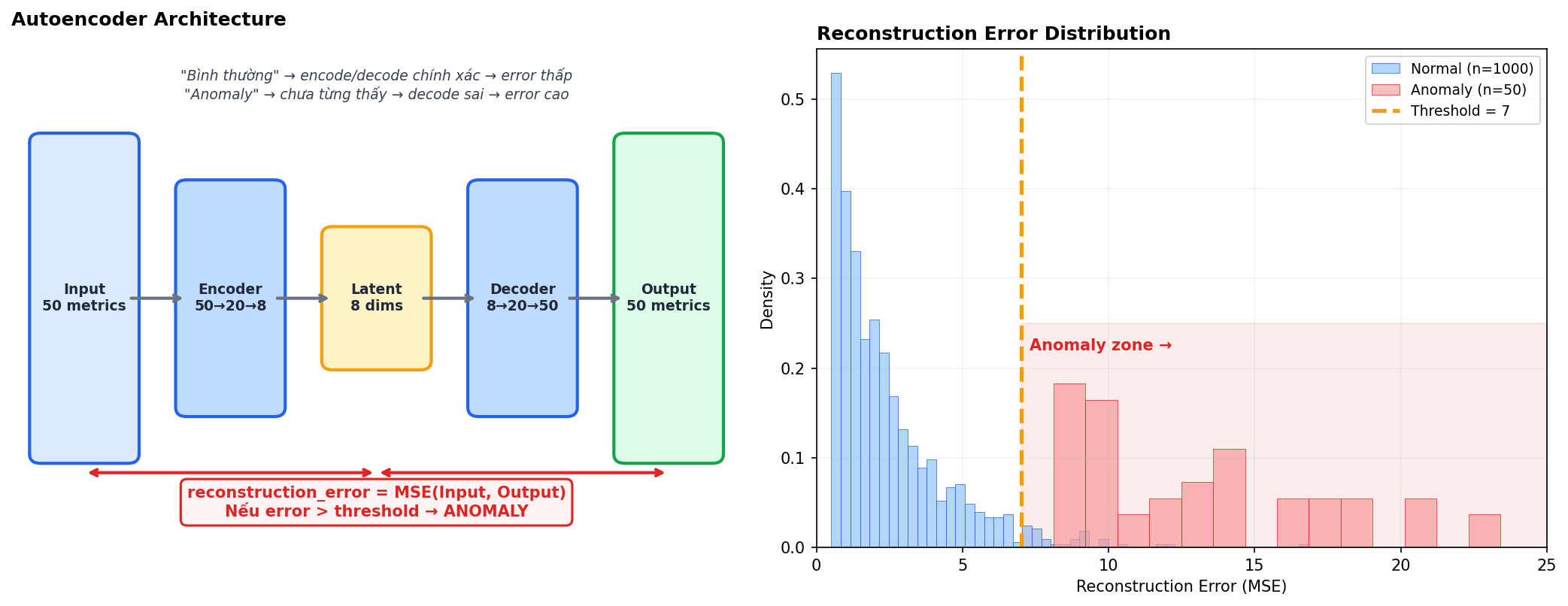
Xem hình: panel trái là architecture (50 metrics → nén xuống 8 dims → giải nén lại 50 metrics). Panel phải là distribution reconstruction error — normal data có error thấp (xanh), anomaly có error cao (đỏ). Threshold ở giữa tách 2 nhóm.
Khi nào dùng: 50+ metric đồng thời, cần detect pattern phức tạp mà IF miss. VD: 1 microservice có 200 metric, anomaly chỉ visible khi nhìn combination của 15 metric cụ thể — Autoencoder tự học combination nào quan trọng.
4.2 LSTM Autoencoder
Giống Autoencoder nhưng dùng LSTM (Long Short-Term Memory) → hiểu thứ tự thời gian — data point trước ảnh hưởng data point sau. Autoencoder thường xem mỗi time step độc lập, LSTM-AE xem cả chuỗi.
Khi nào dùng: Temporal dependency mạnh. VD: latency pattern phụ thuộc vào request 5 phút trước — nếu 5 phút trước latency tăng mà bây giờ không giảm → bất thường. LSTM “nhớ” context, Autoencoder thường không.
Trade-off thực tế:
- Train chậm hơn 10-100x so với IF (cần GPU cho dataset lớn)
- Cần data sạch + nhiều (minimum 1-2 tuần data để train)
- Khó debug khi sai — “black box”, khó giải thích cho ops team “tại sao model bảo anomaly”
- Cần retrain khi system thay đổi (deploy mới, traffic pattern thay đổi)
Rule thực tế: 3σ → STL → Isolation Forest → chỉ khi cả 3 fail mới tính DL. Đây không phải Kaggle competition — production cần explainable (ops team hiểu tại sao alert) + maintainable (không cần ML engineer baby-sit) hơn accuracy thêm 2%.
5. Univariate vs Multivariate — Khi Nào Cần Nhìn Nhiều Metric Cùng Lúc
| Univariate | Multivariate | |
|---|---|---|
| Input | 1 metric (VD: CPU) | Nhiều metric cùng lúc (CPU + memory + latency + error_rate) |
| Phát hiện | Spike/drop trên 1 metric đơn lẻ | Correlation bất thường giữa nhiều metric |
| Tool | 3σ, EWMA, STL | Isolation Forest, Autoencoder |
| Ưu | Đơn giản, dễ debug, dễ explain | Bắt pattern phức tạp |
| Nhược | Miss khi anomaly nằm ở correlation | Khó explain “tại sao anomaly”, cần nhiều data |
Ví dụ chi tiết: Memory leak trong Java service
Scenario: Java service bị memory leak. GC (Garbage Collector) chạy ngày càng lâu, latency tăng dần, cuối cùng OOM crash.
Giờ | Memory | CPU | GC Pause | Latency p99 | Error Rate
──────┼─────────┼───────┼──────────┼─────────────┼───────────
0 | 2.0 GB | 35% | 20ms | 150ms | 0.1% ← bình thường
4 | 2.5 GB | 36% | 45ms | 180ms | 0.1% ← vẫn "OK" từng metric
8 | 3.0 GB | 38% | 120ms | 350ms | 0.3% ← univariate vẫn chưa trigger
12 | 3.5 GB | 40% | 300ms | 800ms | 1.2% ← bắt đầu ảnh hưởng user
14 | 3.8 GB | 85% | 1200ms | 3000ms | 15% ← OOM crash
Tại sao univariate miss tới giờ 12-14:
- Memory: tăng dần 125MB/giờ → rolling 3σ (window 4h) thấy mean tăng dần → band drift theo → mỗi điểm vẫn “trong band”
- CPU: 35-40% → hoàn toàn bình thường, threshold thường ở 80%+
- GC Pause: tăng nhưng monitor riêng, ngưỡng thường đặt 500ms → chưa tới
- Latency p99: tăng nhưng nếu threshold đặt 1000ms → giờ 8 mới 350ms → chưa trigger
Multivariate (Isolation Forest) catch ở giờ 4-6. Tại sao? Vì combination bất thường:
- Memory tăng + GC Pause tăng + Latency tăng + CPU không đổi → bất thường
- Bình thường khi load tăng: memory tăng VÀ CPU tăng (processing nhiều hơn). Nhưng ở đây CPU đứng yên → memory tăng không phải do load → leak
- IF đã thấy hàng nghìn data points “memory tăng + CPU tăng” (bình thường) nhưng chưa bao giờ thấy “memory tăng + CPU không đổi + GC tăng” → anomaly
Đây là sức mạnh multivariate: phát hiện correlation bất thường mà mỗi metric riêng lẻ không đủ thông tin.
6. So Sánh Trực Quan
Hình dưới so sánh 3σ và Isolation Forest trên cùng 1 synthetic time series (1440 data points = 1 ngày data 1-minute, 10 injected anomalies):
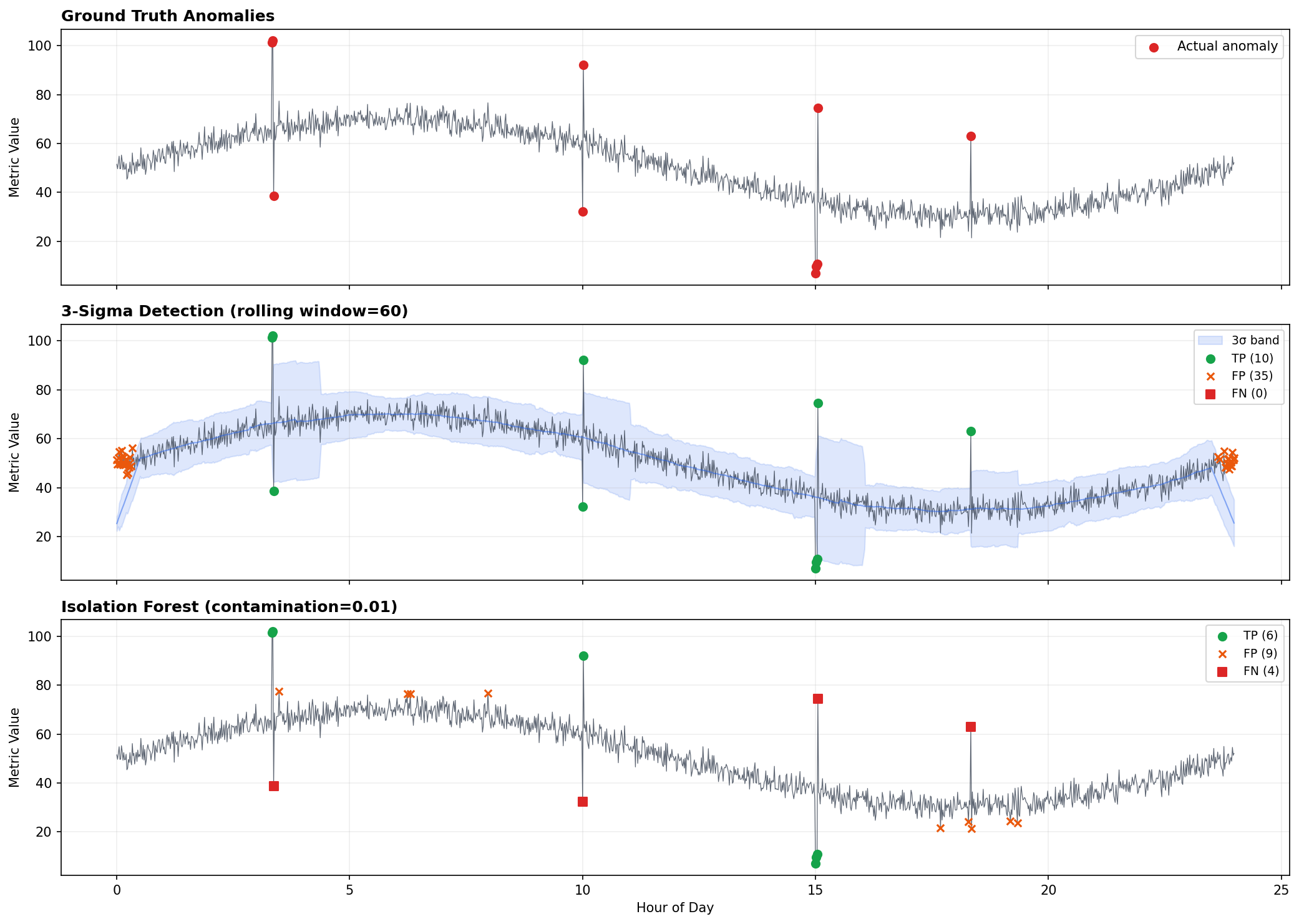
Quan sát:
- 3σ (giữa): bắt được 10/10 anomaly thật (TP=10, recall=100%) nhưng sinh thêm 10 false positive (FP=10, precision=50%). False positive tập trung ở vùng seasonal transition — metric thay đổi nhanh giữa ngày và đêm, 3σ band chưa kịp adjust.
- Isolation Forest (dưới): ít false positive hơn (FP=0, precision=100%) nhưng miss 4 anomaly (FN=4, recall=60%). IF nhìn mỗi point độc lập nên miss anomaly nhỏ lẫn trong noise.
- Trade-off: 3σ recall cao hơn, IF precision cao hơn. Trong AIOps, prefer recall cao (miss anomaly nguy hiểm hơn false alarm), nên dùng 3σ/STL làm first-pass (bắt rộng), IF làm second-pass filter (lọc false alarm).
7. Chọn Phương Pháp
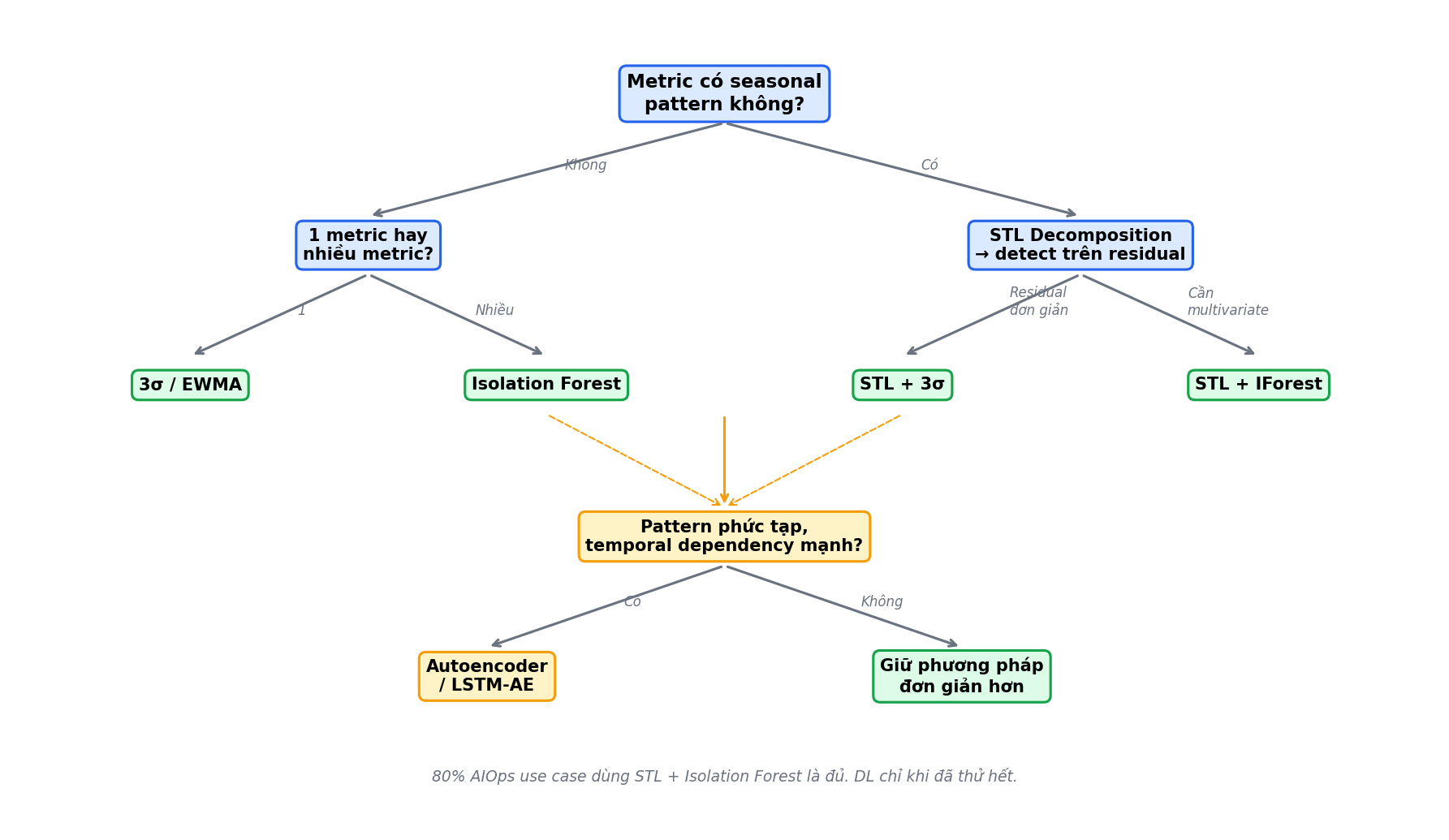
Quick reference:
| Scenario | Phương pháp | Lý do |
|---|---|---|
| Disk usage tăng bất thường | 3σ | Không seasonal, univariate, gần Gaussian |
| Request latency spike ban đêm | STL + IQR | Seasonal (ngày/đêm) + skewed (latency) |
| CPU + memory + latency cùng lạ | Isolation Forest | Multivariate correlation |
| Memory leak chậm | EWMA (α=0.1) | Detect drift, 3σ miss vì drift dần |
| Throughput có weekly pattern | STL (period=168 cho hourly data) | Weekly seasonal |
| 200 metric, pattern phức tạp | Autoencoder | Khi IF đã fail |
8. Feature Engineering cho Time Series
Trước khi feed data vào ML model (Isolation Forest, Autoencoder), cần biến time series thành bảng feature. Raw value không đủ — model cần context.
Tại sao cần feature engineering: ML model nhìn mỗi row (data point) độc lập. Row [value=80] không nói gì — 80 có thể bình thường (nếu data luôn quanh 75-85) hoặc anomaly (nếu data thường ở 30-40). Bạn cần thêm context vào mỗi row: “giá trị trung bình gần đây bao nhiêu?”, “đang tăng hay giảm?”, “1 giờ trước bao nhiêu?”.
| Feature | Code | Mục đích | Ví dụ cụ thể |
|---|---|---|---|
| Rolling mean | s.rolling(60).mean() | Trend gần nhất | “CPU trung bình 1h qua = 42%” |
| Rolling std | s.rolling(60).std() | Độ dao động | “CPU dao động ±3% (ổn định) vs ±15% (bất ổn)” |
| Rate of change | s.diff() | Tốc độ thay đổi | “CPU tăng 5% trong 1 phút — bất thường” |
| Lag features | s.shift(1), s.shift(60) | Context trước đó | “1 phút trước CPU = 40%, giờ 80% = spike” |
| Hour of day | ts.dt.hour | Daily pattern | “20h tối traffic cao là bình thường” |
| Day of week | ts.dt.dayofweek | Weekly pattern | “Chủ nhật traffic thấp là bình thường” |
| Rolling Z-score | (x - roll_mean) / roll_std | Normalized deviation | “CPU đang cách mean 2.5σ” |
| EMA ratio | s / s.ewm(60).mean() | So sánh với trend | “> 1.3 = tăng 30% so với trend gần” |
Full feature pipeline:
def build_features(series, timestamps, window=60):
"""
Biến 1 metric time series thành feature table cho ML model.
Input: 1D array + timestamps
Output: DataFrame với 11 features, sẵn sàng feed vào IF/Autoencoder
"""
s = pd.Series(series, index=timestamps)
features = pd.DataFrame({
'value': s,
'rolling_mean_1h': s.rolling(window).mean(),
'rolling_std_1h': s.rolling(window).std(),
'rolling_mean_4h': s.rolling(window * 4).mean(),
'rate_of_change': s.diff(),
'rate_of_change_5m': s.diff(5),
'lag_1': s.shift(1),
'lag_60': s.shift(window),
'hour': s.index.hour,
'is_weekend': (s.index.dayofweek >= 5).astype(int),
'z_score': (s - s.rolling(window).mean()) / s.rolling(window).std().replace(0, 1e-10),
})
return features.dropna()
Window size cheat sheet:
| Data granularity | Window 1h | Window 4h | Window 1 day |
|---|---|---|---|
| 1 second | 3600 | 14400 | 86400 |
| 1 minute | 60 | 240 | 1440 |
| 5 minute | 12 | 48 | 288 |
| 1 hour | 1 (useless) | 4 | 24 |
9. KPI Đo Lường
Khi evaluate detector, bạn cần đo các metric sau. Đừng chỉ nói “model chạy tốt” — phải có số cụ thể.
| KPI | Công thức | Target | Giải thích |
|---|---|---|---|
| Precision | TP / (TP + FP) | > 0.7 | Trong số alert model báo, bao nhiêu % là thật. Precision thấp (0.3) = cứ 10 alert thì 7 cái false alarm → on-call mệt → bắt đầu ignore alert (alert fatigue). |
| Recall | TP / (TP + FN) | > 0.8 | Trong số anomaly thật, bao nhiêu % model bắt được. Recall thấp (0.5) = miss 50% anomaly thật → outage không ai biết → revenue lost. |
| F1 | 2PR / (P+R) | > 0.75 | Harmonic mean của P và R. Dùng khi cần 1 số duy nhất để so sánh 2 model. |
| TTD (Time-to-Detect) | Anomaly xảy ra → model detect | < 5 phút | Metric quan trọng nhất trong AIOps. Detect sớm 10 phút = MTTR giảm 10 phút = ít impact hơn. |
| False alarm rate | FP / (FP + TN) | < 0.01 | Bao nhiêu % data bình thường bị báo anomaly. > 1% = mỗi ngày hàng trăm false alarm → on-call sẽ tắt alert. |
Recall > Precision trong AIOps. Miss 1 anomaly thật → outage kéo dài, SLA breach, revenue lost, postmortem meeting. False alarm → on-call investigate 5 phút rồi dismiss. Chi phí miss » chi phí false alarm → tune threshold thiên về recall, chấp nhận false alarm rate cao hơn.
References
- Numenta NAB — Anomaly benchmark dataset với labeled anomalies, dùng cho assignment hôm nay
- sklearn IsolationForest — API reference + parameter guide
- statsmodels STL — STL decomposition implementation
- Uber Anomaly Detection — Production AIOps tại Uber, real architecture
- Netflix RAD — Robust Anomaly Detection at Netflix scale
- Twitter Seasonal ESD — Production anomaly detection: STL + ESD test
- Isolation Forest paper — Paper gốc, 8 trang, dễ đọc
- Loghub datasets — Log datasets, cần cho W1-D2
Assignment — Chiều Nay
Trong repo aiops-{name}/w1/day-a/:
Phase 1: EDA & Hiểu Data (1.5h)
- Download 1 dataset từ NAB data/ — gợi ý:
realKnownCause/hoặcartificialWithAnomaly/. Ground truth nằm ở labels/combined_windows.json — mỗi dataset có danh sách anomaly windows dạng[start, end]. Cần download file này và map windows → binary label per row:import json, pandas as pd windows = json.load(open('combined_windows.json')) my_windows = windows['realKnownCause/machine_temperature_system_failure.csv'] # VD: [['2013-12-10 06:25:00', '2013-12-12 05:35:00'], ...] df['timestamp'] = pd.to_datetime(df['timestamp']) df['is_anomaly'] = False for start, end in my_windows: mask = (df['timestamp'] >= start) & (df['timestamp'] <= end) df.loc[mask, 'is_anomaly'] = True print(f"Anomaly rows: {df['is_anomaly'].sum()} / {len(df)}") - Trong
assignment.ipynb:- Load data, plot raw time series
- Tính basic stats: mean, std, skewness (dùng
scipy.stats.skew), min, max - Plot histogram + density → data có Gaussian không? Skewed không? (dùng kiến thức section 1)
- Plot ACF (
statsmodels.graphics.tsaplots.plot_acf) → có seasonal không? Period bao nhiêu? - Kết luận: data thuộc loại nào (stationary? seasonal? skewed?) → phương pháp nào phù hợp nhất, tại sao
Phase 2: Implement 2 Detectors (2h)
- Detector 1 — Statistical: Implement 1 trong (chọn dựa trên EDA):
- Rolling Z-score (3σ) nếu data stationary + gần Gaussian
- STL + 3σ nếu data có seasonal pattern
- IQR nếu data bị skew nặng
- Detector 2 — ML: Isolation Forest:
- Tạo feature table (dùng
build_featuresở section 8 — ít nhất 5 features) - Train Isolation Forest
- Tune
contaminationparameter: thử 0.01, 0.02, 0.05 → ghi lại precision/recall mỗi giá trị
- Tạo feature table (dùng
- Cho mỗi detector: tính precision, recall, F1 dùng ground truth label từ NAB
- Plot: original series + anomalies highlighted cho cả 2 detector (2 subplot, giống hình section 6)
Phase 3: So Sánh & Reflection (1.5h)
Tạo bảng so sánh 2 detector:
Metric Detector 1 Detector 2 (IF) Precision ? ? Recall ? ? F1 ? ? False Alarms ? ? Thử tune threshold / window size / contamination → ghi lại kết quả (ít nhất 3 lần tune)
SUBMIT.mdphải chứa:- Screenshots: plot kết quả anomaly detection (2 detector), bảng so sánh precision/recall
- Log: output khi tune contamination (3 lần tune, mỗi lần ghi contamination + P/R/F1)
- Model artifacts: file
.pklhoặc.joblibcủa Isolation Forest đã train (nhỏ, < 1MB) - Reflection: data thuộc loại gì, chọn method nào, tại sao, detector nào tốt hơn, trade-off, production choice
Bonus (nếu còn thời gian)
- Implement EWMA detector (α=0.1), so sánh 3 phương pháp
- Thử log transform trên skewed data → chạy lại 3σ → so sánh precision/recall trước và sau transform
- Multivariate: combine 2+ NAB series, chạy IF multivariate, so sánh với univariate IF
Knowledge Check (viết tay)
Viết tay trên giấy, chụp ảnh nộp kèm:
- Giải thích skewness là gì, data bị skew thì 3σ sai ở đâu, và 2 cách xử lý khi gặp data skewed
- So sánh 3σ vs EWMA vs STL: mỗi cái detect loại anomaly nào, fail ở đâu, dùng khi nào
- Isolation Forest: giải thích ý tưởng “path length ngắn = anomaly”, tại sao cần feature engineering trước khi feed vào
- Univariate vs Multivariate: cho 1 scenario (VD: memory leak), giải thích tại sao univariate miss và multivariate catch
- Precision vs Recall: trong AIOps tại sao ưu tiên recall, trade-off gì khi tune threshold
Submit: Push lên Git repo trước cuối ngày. File cần có: assignment.ipynb + SUBMIT.md + ảnh chụp knowledge check.